はてなブックマークチームの![]() id:taraoです。はてなブックマークでは、以前はオンプレミスなElasticsearchクラスタを運用していましたが、AWS上にAmazon Elasticsearch Serviceのクラスタを構築して切り替えました。この切り替えではクラスタの再構築に限らず、アップグレードやマッピングの変更にも使える一般的な方法を採用しました。
id:taraoです。はてなブックマークでは、以前はオンプレミスなElasticsearchクラスタを運用していましたが、AWS上にAmazon Elasticsearch Serviceのクラスタを構築して切り替えました。この切り替えではクラスタの再構築に限らず、アップグレードやマッピングの変更にも使える一般的な方法を採用しました。
この記事では、その具体的な方法を紹介します。
一般的な方法を採用したい目的と背景
今回はAWSへの物理的な移設だったため、何かしらクラスタを再構築して、旧クラスタから新クラスタに切り替える必要がありました。このとき、サービスを止めないために以下の要件を課しました。
- 無停止で切り替え可能
- 切り戻し可能
これらの条件は、クラスタの物理的な移設以外のとき、例えばアップグレードや(大きな)マッピング変更の際にも満たされてほしいものです。実は、アップグレードやマッピング変更の場合でも、これらの条件を満たそうとするとクラスタを新たに構築することになります。
そこで、クラスタの物理移設に限らず、他の場合にも同じ手順・構成で実施できるようなクラスタ再構築と切り替えの方法を検討しました。
検討したクラスタ再構築や切り替えの方法
アップグレードやマッピング変更、クラスタ再構築の一般的な方法それぞれに対して、無停止・切り戻し可能の条件を満たすにはどうすればよいかを、いったん考えてみましょう。
1. ローリングアップグレード
公式ドキュメントの通り、1ノードずつ停止・アップグレードして、ノードの復旧を待つという方法です。アップグレードできる範囲は、マイナーバージョン間もしくは1段階のメジャーバージョン間のみです。
クラスタ全体としては無停止ですが、これだけでは切り戻しはできません。切り戻しできるようにするには、別クラスタを構築して片方だけアップグレードすることになります。しかし、そうすると今度は(そのままでは)無停止ではなくなります。新クラスタ構築完了後(切り替え前)に旧クラスタに書き込まれたデータを、新クラスタに何らか反映させる必要があるためです。
また、どうせ別クラスタを構築するなら、ローリングアップグレードする必要もなく、最初から新バージョンでクラスタを構築すればよいはずです。
2. スナップショット・リストア
インデックスのスナップショットを取り、それを別クラスタにリストアすれば、インデックスをまるごとコピーできます。このとき、新クラスタはメジャーバージョンを1段階上げておいても大丈夫です。
ただし、スナップショットを取ってからリストアが完了するまでの間に旧クラスタに書き込まれたデータは新クラスタには反映されないため、無停止ではできません。
また、バージョンがアップグレードする方向にはリストアできてもダウングレードする方向にはできないため、新クラスタの稼動を開始してしまってから切り戻す(逆向きのスナップショット・リストアを実施する)こともできません。
3. クラスタ横断レプリケーション
これはElastic Stackサブスクリプションのプラチナレベルの機能です。さらに、AWS上のElasticsearch Serviceでは使えません。
この方法でアップグレードする場合は、新クラスタ(follower indexを持つ方)のバージョンを上げた後、参照系だけ新クラスタに向けることができ、この時点なら旧クラスタに切り戻しが可能です。
4. Reindex API
このAPIを用いると、あるインデックスを別インデックスにコピーすることができます。別インデックスはバージョンの異なる別クラスタ上のものでもよいため、アップグレードする際や物理的な移設の場合にも使えます。また、スクリプト機能で記述可能な程度の軽微なマッピング変更をしながらインデックスをコピーすることもできます。
ただし、インデックス上のドキュメントにはすべて_sourceフィールドが設定されている必要があります。また、無停止で切り替えるためには、インデックスのコピーの開始から終了までの間、ドキュメントの更新処理を両方のクラスタに対して適用する必要があります。
二重に書き込み(ダブルライト)する場合、新クラスタに直接書き込まれたドキュメントと、旧クラスタからコピーしてきたドキュメントの衝突を避けるため、ドキュメントのバージョニングが必要となるかもしれません。
5. アプリケーションコードによる再インデキシング
これが今回採用した方式です。
Elasticsearch上のインデックスを、別のマスタデータ(RDBMS上のデータなど)を元にして更新しているのであれば、その更新のためのアプリケーションコードを全ドキュメントに対して実行することで、インデックス全体を再構築できるはずです。
全件のインデキシング(バッチ処理)とは別に、通常稼動時のインデックス更新処理(オンライン処理)も並行して走らせて、新旧両方のクラスタを更新すれば、無停止での切り替えにも対応できます。
Reindex APIの場合と同様、バッチとオンラインの更新処理が衝突しないように気をつけなければなりませんが、マスタデータは別にあるため_sourceフィールドの有無には左右されません。旧クラスタと新クラスタで書き込み処理を分けることで、バージョンやマッピングが異なる場合にも対応できます。
目的・条件による取りうる方法のまとめ
以上をまとめると、下の表のようになります。
| 軽微なマッピング変更 | 大幅なマッピング変更 | バージョンアップ | 物理移設 | 無停止 | 切り戻し可 | |
|---|---|---|---|---|---|---|
| ローリングアップグレード | × | × | ○ | × | ○ | × |
| スナップショット・リストア | × | × | ○ | ○ | × | × |
| クラスタ横断レプリケーション | × | × | ○ | ○ | ○ | ○ |
| Reindex API | ○ | × | ○ | ○ | ○ | ○ |
| App再インデキシング | ○ | ○ | ○ | ○ | ○ | ○ |
今回はAWSのElasticsearch Serviceへの移設のため、クラスタ横断レプリケーションを利用する余地はなく、無停止で物理移設するにはReindex APIもしくはアプリケーションコードによる再インデキシング(App再インデキシング)のどちらかになります。
今後、大きなマッピング変更を伴うクラスタの再構築を予定していることもあり、その際にも仕組みを流用できるよう、後者の手法を選択しました。
採用した再インデキシング手法の詳細
新旧両方のクラスタを更新するアプリケーションコードによる再インデキシングは、次の手順で実施することになります。
- ダブルライトの開始
- バッチ処理による再インデキシングの実行
- 新クラスタへの切り替え
- ダブルライトの停止



順を追って詳細を説明していきます。
ダブルライトをどのように実現するか
基本的には、旧クラスタに対してこれまで実施していたすべてのオンラインのインデックス更新処理を、新旧両方のクラスタに対して行うようにするだけです。
ただし、以下の点には気をつける必要があると思います。
- インデキシングに失敗したときの処理
- リトライしたい
- 最終的に片方だけ失敗するとまずい(少なくともアラートしたい)
- ダブルライト開始・停止のしやすさ
- 設定の変更などで切り替えられるとよい
- 新旧クラスタ向けの別々のコードの混在を避けて見通しよくする
- マッピング変更する場合も、異なるマッピングに基づく処理の混在を避けたい
このため、インデックス更新処理を非同期化するのがよいと結論づけました。
Elasticsearchのインデックス更新は、index.refresh_intervalで設定した間隔でしか反映されず(Refresh APIを明示的に呼ばない限り)、もともと同期的に更新が反映される前提は置けないため、インデックス更新処理を非同期化してもとくに問題ないはずです。
インデックス更新処理が非同期化されていれば、ダブルライト時には非同期ジョブを二重に投入するだけで済み、リトライや失敗時のアラートもジョブキューの機能に任せることができます。
ジョブを実際に処理するワーカは、新クラスタ向けのものと旧クラスタ向けのものを別にしておきます。こうすると、各ワーカは単一のクラスタに対する更新処理に専念できます。
非同期ダブルライトのアーキテクチャ
はてなブックマークのシステムではジョブキューとしてFireworqを採用しており、ワーカは単なるHTTPサーバでよく、ふだんはジョブを投入したアプリケーションサーバ自身が非同期ジョブのワーカの役割も兼ねています。
ダブルライトするには、新クラスタへの書き込み(マイグレーション)の設定が施されたアプリケーションサーバを用意すれば済みます。また、Elasticsearchを新クラスタに切り替えた後には、切り戻しを想定して旧クラスタへの書き込み(逆マイグレーション)のためのワーカも必要になります。
アプリケーションサーバには、各ロールに合わせて以下を設定できる必要があります。
- 利用するElasticsearchクラスタ
- プライマリの非同期ジョブ(もとのインデックス更新ジョブ)に指定するワーカ
- バックアップの非同期ジョブ(ダブルライトのためのジョブ)に指定するワーカ
各ロールにおける接続先の設定値は、以下のようになります。
| Elasticsearchクラスタ(⑤、⑤') | プライマリワーカ(④) | バックアップワーカ(④') | |
|---|---|---|---|
| アプリケーションサーバ(切り替え前) | 旧クラスタ | 自分自身 | マイグレーションサーバ |
| アプリケーションサーバ(切り替え後) | 新クラスタ | 自分自身 | 逆マイグレーションサーバ |
| マイグレーションサーバ | 新クラスタ | (自分自身) | なし |
| 逆マイグレーションサーバ | 旧クラスタ | (自分自身) | なし |
切り替え前のアプリケーションサーバは旧クラスタに読み書きし、インデックス更新ジョブは自分自身(プライマリの更新ジョブのワーカ)とマイグレーションサーバ(バックアップの更新ジョブのワーカ)の両方に投げます。
切り替え後は、アプリケーションサーバは新クラスタに読み書きするようになり、プライマリの更新ジョブは自分自身に、バックアップの更新ジョブは逆マイグレーションサーバに投げることで旧クラスタへの書き込みも継続し、いつでも切り戻せる状態を維持します。
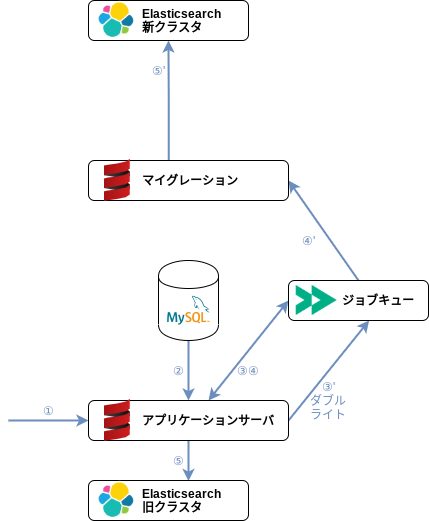

こうすることで、Elasticsearchクラスタの切り替え・切り戻し作業はアプリケーションサーバへの設定の反映だけになります*1。
マイグレーション・逆マイグレーションのワーカに、Elasticsearch以外の状態変更(データベースへの書き込みなど)を許すと、システム全体で齟齬が発生する懸念があります。インデックス更新のために必要な情報はジョブのペイロードにすべて載せて、マイグレーション・逆マイグレーションワーカではElasticsearch以外のミドルウェアへの(書き込み)アクセスやAPIの呼び出し設定は潰してしまっておくと安心できます。
大きなマッピング変更を伴う場合でも、マイグレーション用ワーカと切り替え後のアプリケーションサーバは新マッピングを前提としたコードベースに、逆マイグレーション用のワーカと切り替え前のアプリケーションサーバは旧マッピングを前提としたコードベースにすることで対応できます。このときもやはり、新旧両方のマッピングに必要な情報のすべてをジョブのペイロードに載せる必要があります。
バッチ処理によるデータ移行
ドキュメント総数がそれほど多くない場合は、通常のドキュメントのインデキシングと同じ方法を使って、システムに存在するすべてのドキュメントをインデックスすればよいだけです。件数が多い場合に速度を出すには、Bulk APIを使う必要があるかもしれません。
はてなブックマークでは、Bulk APIで指定のドキュメントを(再)インデックスする内部APIと、システムに存在するすべてのドキュメントを列挙する内部APIをドキュメントの種類ごとに用意して、バッチ処理を実施しました。
データの移行は不備があってやり直す場合があるため、並列度を上げてなるべく素早くイテレーションを回すのが望ましいと思います。ある程度の負荷が予想されるため、通常の本番アプリケーションサーバとは別に実行できるとよいでしょう。前述のマイグレーション用ワーカはそのままバッチ処理の用途にも使えます。
楽観的ロックによる整合性の維持
新クラスタでは、オンラインのインデックス更新とバッチ処理によるインデックス更新の両方が走ることになり、タイミングによっては同一ドキュメントに対して相異なる更新をしようとすることになります。
そうすると、あるドキュメントを内容Bに更新したはずが更新前の内容Aに戻ってしまうことも、例えば以下のようにタイミングによってはありえます。
- [バッチ]ドキュメント1の内容Aを、DB(マスタデータ)から読み出す
- [オンライン]ドキュメント1を、DB上で内容Bに変更
- [オンライン]ドキュメント1のインデックスを、内容Bに更新
- [バッチ]ドキュメント1のインデックスを、内容Aとして書き込む
Elasticsearchのインデックス上のドキュメントにはバージョンの概念があり、ドキュメントのexternalなバージョン(Elasticsearchの外から与えるバージョン)を適切に管理することで、古いバージョンのドキュメントで新しいバージョンのドキュメントを上書きするのを防ぐことができます(いわゆる楽観的ロック)。
上の例は以下のようになり、古いバージョンでの上書きを失敗させることができます。
- [バッチ]ドキュメント1の内容Aを、DBから読み出す〈バージョン1〉
- [オンライン]ドキュメント1を、DB上で内容Bに変更〈バージョン2〉
- [オンライン]ドキュメント1のインデックスの内容を、バージョン2に更新
- [バッチ]ドキュメント1のインデックスの内容を、バージョン1として書き込む
最後のインデックスの書き込みは、409 Conflictとなって失敗します。
ただし、インデックスの更新では、常にドキュメントまるごと置き換える(Update APIではなくIndex APIを使っている)前提です。
externalなバージョンの与え方
ドキュメントのバージョンとして使える値を計算するタイミングには、大きく分けて2通りあります。
- マスタデータに変更があるたびに、単調増加な値をいっしょに記録する
- インデックスに書き込むための内容を読み出すときに、この値もいっしょに読む
- マスタデータからの読み出し前に、単調増加な新たな値を発行する
- 変更後に、必ず新たにマスタデータを読み出してインデックス更新する
バージョンをマスタデータそのものに含めておけば、インデックスされるドキュメントの内容とバージョンの対応が確実に取れますが、マスタデータが例えばデータベースの複数のテーブルからなる場合、どのテーブルの変更でも確実にバージョンがインクリメントされるように気をつけなければなりません。また、バージョンの書き換えのためにおそらくトランザクションも必要となり、マスタデータの更新そのものが複雑化しそうです。
マスタデータの読み出し前にバージョン値を発行する方式の場合、マスタデータからの読み出しは必ず値の発行の後にする必要があります。はてなブックマークの場合は、マスタデータを更新したらドメインイベントを発火していて、そのイベントハンドラ内であらためてマスタデータからの読み出しとインデキシングをするようになっているため、この方式がやりやすいと判断しました。イベントハンドラのセッションの先頭でバージョン値を発行しています。
単調増加なバージョン値の発行にも、さまざまな方法があります。
- データベースなどで単純に値をインクリメント
- 時刻を元にした値を計算
- 採番システム
マスタデータにバージョン値を記録する場合は、そのデータストア自身でインクリメントした値を計算するのが最も簡単だと思います。
なんらかのセッションの先頭でバージョン値を発行する場合は、セッション開始時刻を元にバージョン値を決定してもよいかもしれません。ただし、同一ドキュメント・同一時刻の複数回の更新や時刻のずれを気にする必要がある場合は注意が必要です。もし気になるなら、Snowflakeのような仕組みの実装や、katsubushiのような採番システムの利用を検討した方がよいでしょう。
はてなブックマークのシステムは書き込み頻度はそれほど高くなく、アプリケーションの性質として同一のドキュメントを複数セッションから同時に書き換えることはあまりないため、時刻をベースに(内部的に一気に複数回書き換える場合があることへの対応として)セッション内でインクリメントする値を含めたものを利用しました。
楽観的ロックで削除が発生する場合の対応
ドキュメントのバージョンによる楽観的ロックは、単純にやろうとするとドキュメントの削除に対応できません。まだドキュメントが存在しない場合は、どんなバージョンのドキュメントでも追加できてしまうためです。
例として、以下のような状況を考えます。DBはこれまでと同様にマスタデータです。
- [バッチ]ドキュメント1の内容Aを、DBから読み出す〈バージョン1〉
- [オンライン]ドキュメント1を、DB上で削除〈バージョン2〉
- [オンライン]ドキュメント1のインデックスを、バージョン2と指定しつつ削除
- [バッチ]ドキュメント1のインデックスの内容を、バージョン1として書き込む
最後の段階でドキュメント1はもう存在しないため、コンフリクトも発生せず書き込みが成功してしまいます。
Elasticsearchではこの状況を避けるため、インデックス上のドキュメントとしては削除済みで存在しなくても、内部的には一定期間データを残してバージョンの衝突確認にだけ用いる機能を備えています。この「一定期間」はindex.gc_deletesで設定できます。具体的な値は、バッチ処理のデータ移行がオンライン処理に対してどれくらい遅れる可能性があるかを考えて決めましょう。
クラスタ切り替えを実施する
実際の切り替え作業は次のように実施しました。
負荷試験
AWSへ移設することで、オンプレミス環境より簡単にノードを増やすことが可能になるため、各ノードの性能は抑え、スケールアップよりもスケールアウトの戦略をより積極的に取っていくことになりました。
そうなるとパフォーマンス特性もかなり変わってくるため、事前に新クラスタが実際のクエリに耐えられるかどうかの負荷試験をしました。
方法としては、本番環境でのリクエストのログを取っておきGatlingでリプレイするというものです。この結果を見て(少し厳しめの)インスタンスタイプとノード数を決めました。
切り替え・切り戻し
既に説明した通り、切り替え作業はアプリケーションサーバの設定変更を反映するだけです。切り戻し可能なアーキテクチャになっているため、時間をおいて1台ずつ反映することもできます。
切り替わったアプリケーションサーバが増えて、もし新クラスタが負荷に耐えられなくなりそうになったら切り戻すという作戦です。
新クラスタの性能は絞り気味にしていたため、実際に切り戻しは2回発生し、切り戻しせずにElasticsearchクラスタのノード数をその場で増やしたのも含めて、計4回の切り替えの末に全工程が完了しました。
実施後の課題と展望
性能を絞り気味にしていたとはいえ、負荷試験の結果と比較しても本番環境の方が圧倒的に負荷が高い結果になりました。
原因としては、Gatlingでのリプレイではリクエスト間隔までは再現されないことや、負荷の高いクエリがたまたま含まれていなかったり、直前の状態によって負荷が高まるかどうかが変わることなどが考えられます。もう少し精度の高い負荷試験をするには、シャドウプロキシで本番リクエストを新クラスタに一定期間流すべきでした。
とはいえ、切り戻しは非常にスムーズにでき、Elasticsearchクラスタの負荷が徐々に高まったときに各監視メトリックの状態がどうなるかの実験にもなったのはよかったと思います。今後予定しているアップグレードや大きなマッピング変更でもパフォーマンス特性が大きく変わる可能性があり、今回の知見はまた活かせそうです。
まとめ
Elasticsearchクラスタのアップグレードやマッピング変更、物理移設などを無停止かつ切り戻し可能な状態で実施できる手法を紹介しました。
実際に切り替えまで実施してみて、ポイントとなったのは以下の2点でした。
- 非同期ダブルライト
- マイグレーションと逆マイグレーションのワーカを用意する
- ドキュメントに
externalなバージョンを付与して整合性を保つ- 削除がある場合は、
index.gc_deletesを設定する
- 削除がある場合は、
*1:ここではアプリケーションサーバは単一の想定ですが、切り替え前と切り替え後のアプリケーションサーバを両方とも立ててしまって、アクティブなアプリケーションサーバを切り替えるという方法でもうまくいくはずです