AWSの東京リージョンでFargate Spotを「中断されたら困る」割合で利用している場合、2024年10月は見直し時かも知れません。
はてながECS Fargateで運用しているWebサービスの多くは、状況に応じてリクエスト数≒負荷が増減します。
これに対して、リクエストを受け持つECSサービスのタスク数をオートスケールさせてコスト最適化を図っています。 ボトルネックはCPUで、CPU使用率を追跡していることが多いでしょうか。
オートスケールで追跡する使用率にはスケールアウトまでの間の負荷に耐えるための余裕を持たせます。 この余裕の部分をSpotタスクで確保することで更にコストを削減できます。
AWS Fargate Spotの発表で示されているユースケースでは以下に該当します。
また高可用性を求められるウェブサイトやAPIサーバーのように、ECSサービスの一部となるタスクに対してもFargate Spotを適用することができます。
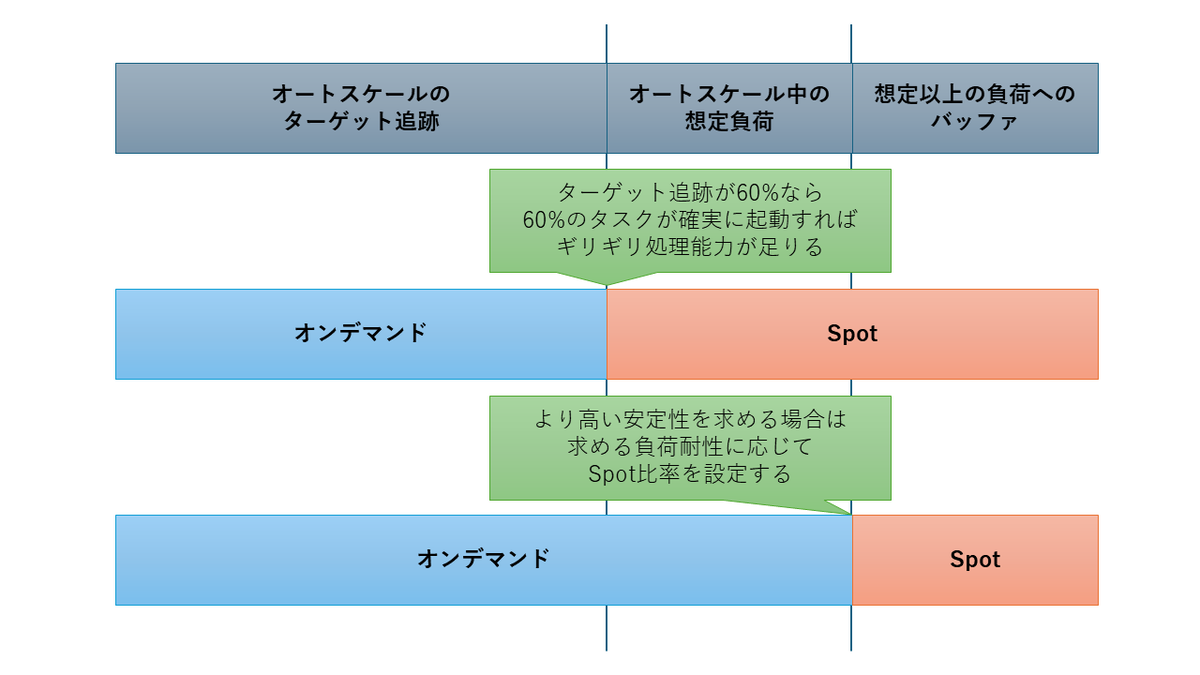
ここまでが教科書通りの設定ですが、これまでの運用上Spotタスクが全て中断されたことはなく、いくつか中断されても(恐らく他のホストマシンで)概ねその直後にタスクが起動していました。 このような実態を当てにするなら、理論値ではなくよりコストを優先した設定、Spot比率とすることが可能です。

可能「です」というか、可能「でした」。
ここ数ヶ月で東京リージョンではタスクの中断が増えており、中断直後にキャパシティ不足で起動しない場面も散見されています*1。

実際、はてなではそうした際にコスト優先で攻めた設定をしていたサービスでコンピューティング能力が不足する状況が発生しました。
これに対しては素直にSpot比率を下げる方向に見直す形で対応しています。
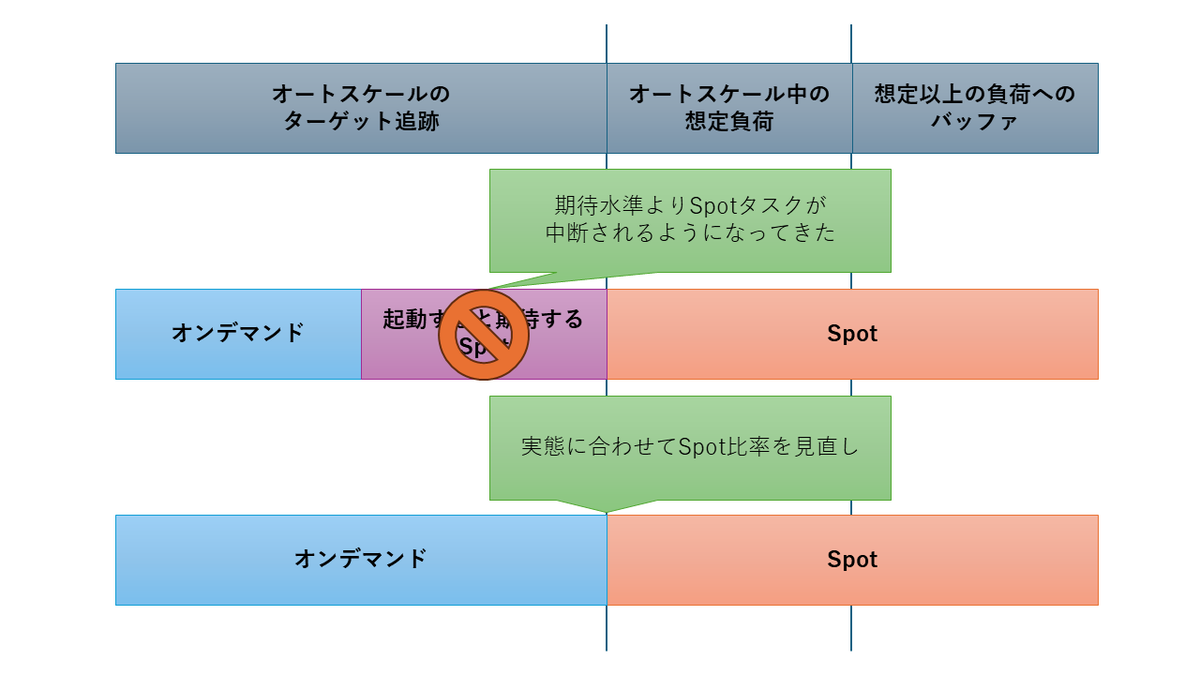
求めるサービスレベルとの相談にはなるかと思いますが、攻めた設定でSpotタスクを運用している方は中断具合を確認し、比率を見直すのがよいかもしれません。
とは言え、既に同様の設定で運用されている方は、同様に中断が「攻めた設定」に影響するレベルで増えていることは観測されているかと思います。
しかし、こうした「AWSクラウドの空きキャパシティ」の状況はAWSに問い合わせても回答を貰えません。それ自体は「そういうもの」ですが、インターネット上に実態の情報が乏しいため「我々がap-northeast-1でX86_64のFargate Spotを運用する限りではこうでした」を共有したかった次第です。多少なりとも参考になりましたら幸いです。
この記事は ![]() id:koudenpa が書きました。
id:koudenpa が書きました。
余談
ギリギリのSpot比率を極めたい場合は、土日が攻め時かも知れません。