システムプラットフォームチームで SRE をしている id:masayoshi です。
今年もISUCON14の開催が決定しましたね!
ISUCONとはLINEヤフー株式会社が運営窓口となって開催している、お題となるWebサービスを決められたレギュレーションの中で限界まで高速化を図るチューニングバトルです
ISUCONは、世の中に実際にありそうなWebサービスを題材に、明確なボトルネックがあるコードかつ全体のコード量もすぐ読める量なので、パフォーマンスチューニングの練習にはもってこいです。
適切なパフォーマンスチューニングをするためには、まず計測してシステム上のどこにボトルネックが存在してパフォーマンスが悪化しているのかを把握する必要があります。
このように、どこで、何が起こり、パフォーマンス上の問題やエラーがおこっているのかを把握できる能力を Observability といいます。
最近、インターネット上や社内のSREが、Observability がどうのこうのとか言っているけどよくわからんなー、何が良いんだ?どういう概念なんだろう?って人も多いかと思います。
そこで今回は、去年のISUCON13を題材にできるだけ構築や実行が簡単なツールを利用して Observability を手軽に体験してもらおうという記事です。(ISUCON対策にもなるぞ!)
システム全体の把握や、アプリケーションコードを読み込まなくても、メトリクス、トレース、ログを見ることによってボトルネックがどこにありそうかを推定できるかどうか試してみましょう。(なので、アプリケーションコードはあまり読まないで試してみてね!)
ISUCON13について
ISUCON13の課題とコードはこちらで公開されています。ボトルネックの解説もありますので、本記事と併せて確認してみると良いでしょう。(解説はネタバレにもなってしまうので、本記事を読み終わった後に見ましょう!)
コードを手元に落としてきたら、「docker compose での構築方法」、「ベンチマーカーの実行」を参考にして、手元で実行する環境を構築しましょう。 手元で動くようになったら、計測をしていきましょう!
メトリクス、トレース、ログについて
Observability を実現するための手法としてよく利用されるのは、メトリクス、トレース、ログの3つのデータです。
- メトリクス
- CPU使用率などの一定期間ごとに測定した数値データ(時系列データ)のことです。
- トレース
- リクエストがどんな処理をしたか、どれぐらいの処理時間だったかを示す構造化されたデータのことです。
- ログ
- どんなイベントがいつ発生したのかを示すテキストデータです。
メトリクスとログはイメージがしやすいと思いますが、トレースは文字だけだとわかりにくいので、図にしてみました。

今回の例だと、ユーザー(ベンチマーク)からリクエストが来て、Nginx、アプリケーション、MySQLというWeb, App, DBの3層構造でリクエストを処理します。
メトリクスやログはそれぞれNginxのアクセスログやCPU使用率、リクエスト数など、ミドルウェアやプロセスごとの数値データやイベントを出力していますが、トレースはユーザーの1リクエストで何が起きたのかを記録できます。
それでは、メトリクス、トレース、ログを使いながら、ボトルネックを探していきましょう!
メトリクスで全体を把握!
まずはメトリクスからどこが一番重い処理をしていそうか確認してみましょう。
本番環境では、例えばCloudWatch Metrics や Cloud Monitoring など利用しているIaaSが提供しているサービスを利用したり、弊社が提供している監視SaaS Mackerelを利用したりして、グラフにするのが一般的ですが、
今回はローカル環境かつdocker composeで実行しているので、シンプルにdocker container stats コマンドを利用して、リソースの使用率を確認していきます。
ベンチーマーク実行中に、 docker container stats コマンドを実行してリソースの使用量を確認してみましょう。
私が実際に計測した結果を以下に記載します。
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 27531f3de130 nginx 0.00% 15.64MiB / 31.23GiB 0.05% 5.88kB / 306B 19.1MB / 4.1kB 9 0e7dd7bea721 webapp 92.63% 104.7MiB / 4GiB 2.56% 486MB / 175MB 71.6MB / 0B 17 f54fec33ea8b powerdns 3.19% 70.64MiB / 31.23GiB 0.22% 2.8MB / 1.25MB 49.5MB / 8.19kB 11 9299c23ed4a9 mysql 453.50% 563.8MiB / 31.23GiB 1.76% 51.1MB / 474MB 106MB / 456MB 56
CPU使用率はMySQLが一番高い結果になりました。メモリはそんなに使っていないようです。I/OはMySQLとアプリケーションがそこそこ使っていそうですね。
これらの結果からMySQLがボトルネックになっている可能性が一番高そうなことがわかりますが、どのような処理でパフォーマンスが悪くなっているかはわからないですね。
パフォーマンスチューニングに慣れている人なら、この時点でMySQLの詳細を調べるために、slow query logを出して遅いクエリの特定やテーブルスキーマでインデックスの確認、アプリケーションコードを読んで、N+1の処理を指定そうな箇所の特定し修正なども可能かと思いますが、今回の目的は Observability の体験ということで、トレースを活用し、実際にアプリケーションがどのようにMySQLを利用しているのか確認してみましょう!
トレースで問題箇所の把握!
トレースを利用するには、アプリケーションのコードを一部変更したり、トレースの構造化されたデータを可視化するツールと、それを送るためのエージェントが必要になっていきます。
今回は、OpenTelemetry に対応している OpenObserve という OSS を利用して、トレースを可視化してみます。
いくつかコードの変更などがありますので、私の方でISUCON13リポジトリをフォークして用意したこちらのリポジトリを新たに手元に持ってきてadd-traceブランチでベンチマークを実行してみてください。
本記事では Observability の体験ということで、詳細な設定の説明やコード解説については省略させていただきますが、変更点などが気になる方はこちらを確認してみて下さい。
変更版の方では、http://localhost:5080 にアクセスし、で OpenObserve にログインできるようになっています。
- ユーザー名
- root@example.com
- パスワード
- Complexpass#123
それでは、Traceを確認してみましょう。
左のメニューからトレースを選んで、Durationのminを1000msぐらいにして右上のクエリを実行を実施すると遅かったリクエストが表示されていると思います。
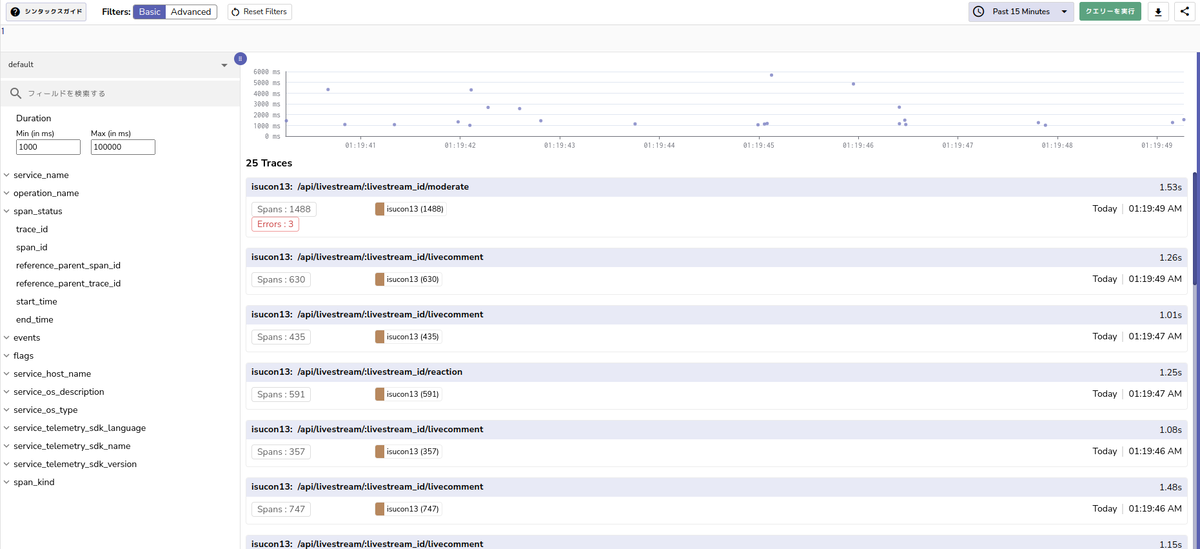
トレースの中でもSpansが多いトレース(例えば /api/livestream/:livestream_id/livecomment など)を選んでみましょう。

大量のDBリクエストが地層のように表示されていると思います。
一つ一つのSQLの実行時間は短いシンプルなSELECTですが、同じテーブルに対して大量にSQLが実行されていることがわかります。for文でSQLを実行してN+1問題が発生していそうです。
他のトレースを見ていけば、/api/livestream/search 以外にもいくつかのエンドポイントでN+1問題が発生してそうなことがわかります。
トレースを設定することで、どんなアプリケーションコードが実行されているのかを知らなくても、どこで効率の悪いSQLを実行しているかを把握することができました。
それでは、実際にアプリケーションのコードを直しに行くか!という気持ちになりたいところですが、せっかくなので、MySQLのスロークエリログも確認してみましょう。
ログで詳細も把握!
先程の変更版リポジトリでは、MySQLのスロークエリログも有効になっていますので、pt-query-digest を使ってMySQLのスロークエリログを集計してみましょう。
スロークエリログはリポジトリの development/data/slow.log に出すように設定してあります。
pt-query-digest の結果はこちらです。(ローカル環境のパフォーマンスによって一部結果が異なる可能性があります。)
pt-query-digest ./development/data/slow.log > query_summary.txt
# 14.1s user time, 160ms system time, 55.61M rss, 392.49G vsz # Overall: 215.15k total, 101 unique, 1.42k QPS, 0.76x concurrency _______ # Attribute total min max avg 95% stddev median # ============ ======= ======= ======= ======= ======= ======= ======= # Exec time 115s 1us 220ms 535us 2ms 2ms 214us # Lock time 390ms 0 36ms 1us 2us 98us 1us # Rows sent 143.38k 0 7.32k 0.68 0.99 24.92 0 # Rows examine 151.14M 0 14.01k 736.59 2.06k 1.67k 0.99 # Query size 43.89M 5 1.94M 213.91 400.73 5.23k 84.10 # Profile # Rank Query ID Response time Calls R/Call V/M # ==== =================================== ============= ===== ====== ==== # 1 0x42EF7D7D98FBCC9723BF896EBFC51D24 17.3425 15.0% 15960 0.0011 0.00 SELECT records # 2 0xF1B8EF06D6CA63B24BFF433E06CCEB22 12.7606 11.1% 5451 0.0023 0.02 SELECT users livestreams livecomments # 3 0xF7144185D9A142A426A36DC55C1D2623 12.0741 10.5% 4017 0.0030 0.00 SELECT livestream_tags # 4 0x3D83BC87F3B3A00D571FFC8104A6E50C 11.3525 9.8% 11135 0.0010 0.00 SELECT records # 5 0xDB74D52D39A7090F224C4DEEAF3028C9 10.6929 9.3% 5451 0.0020 0.00 SELECT users livestreams reactions
この結果を見ると、トレースで確認したように、異常に呼び出されている回数が多いテーブルがいくつか存在することがわかります。
これを見ると、recordsテーブルが総合的に一番処理時間が多い結果になっていますが、実はこのrecordsテーブルはアプリケーション側から利用されているテーブルではなく、PowerDNSが利用しているテーブルになります。
レギュレーションを読めばわかりますが、ISUCON13ではPowerDNSがアプリケーションとは別に存在しており、そこにDNSの水責め攻撃が来るベンチマークになっています。
MySQLの負荷を高めているのは、トレースで判明したアプリケーションのN+1問題のクエリだけではなく、PowerDNSが実行しているSQLも非常に重いクエリになっているということです。
そのため、ボトルネックを解消するにはPowerDNSへの対策をすることも必要となってきそうです。
このように、一見トレースだけですべてをボトルネックを把握できたかのように思えても、ユーザーからのリクエスト外だったり、今回のようなトレースで検出しにくいミドルウェア自体からのリクエストが問題である場合もあります。
メトリクス、トレース、ログはそれぞれ検出しやすい項目や範囲が異なるため、それぞれの長所を活かしつつ、調査のときはこれら3つを適切に利用して調査を進めましょう。
メトリクス、トレース、ログの詳しい使い分けなどはこちらの資料を参考にしてみてください。
把握したボトルネック箇所
メトリクス、ログ、トレースを活用して把握できたボトルネックは以下のようになります。
- いくつかのエンドポイントでN+1問題が発生している
- DNSの水責め攻撃によるPowerDNSによるMySQLへのクエリが遅い
ここでISUCON13の問題解説を見てみると、把握できたボトルネックと把握できていないボトルネックがあることに気が付きます。
例えばインデックスが効いていないなどは、MySQLのテーブル情報をメトリクスにして投稿すればインデックスが効いていないスキャンが多いことに気が付けるかもしれません。
とはいえ、pt-query-digestやトレースで把握したSQLを改善しようとExplainすればわかることなどもありますので、初動として把握するには十分な範囲はできているかなと思います。
また、本番環境でもすべてを把握できるようにメトリクス、トレース、ログの設定を網羅するのは大変ではあるので、なんか全体把握の調査の初動として情報量が不十分だと感じたときに設定を追加して Observability を強化していけば良いでしょう。
まとめ
このように、システム全体のことやアプリケーションに詳しくなくても、メトリクスやトレース、ログからどこが遅いのか、これから何に対応していかなければいけないのかが大体わかるようになりました。
これがまさに Observability であり、今回はISUCON13の過去問を通して簡易的に体験してもらいました。
実際のWebサービスではこれより複雑なシステムやコードで動いていることが多く、それらすべてを把握するのは開発チームでも困難です。
把握していなくても、メトリクス、トレース、ログから状態が推定できるようなシステム(Observabilityのあるシステム)を構築できるようにしていきましょう!
宣伝
2つ宣伝をさせてください!
10/22に「モニタリング・オブザーバビリティの変遷とこれからの展望!」というイベントを実施しますので、今回の記事でObservabilityに興味を持った方はぜひいらしてください。 弊社監視SaaS Mackerelのイベントではありますが、Mackerelの機能に限らず Observability,監視関連 の登壇やパネルディスカッションもありますので、Mackerelは使ってないよ!という方でもお気軽に参加してください!
モニタリング・オブザーバビリティの変遷とこれからの展望! - connpass
もう一つは弊社の分散トレーシングサービス Vaxila(ヴァキシラ) のご紹介です。
監視SaaS Mackerelではメトリクスしか扱えませんでしたが、Vaxilaによりトレースも扱えるようになりました!
現在は体験版という状態なので、機能、安定性という点ではまだまだですが、OpenTelemetryに対応したトレースを触ってみたい!という方はぜひ検討していただければと思います。