こんにちは、Mackerel チーム SRE の ![]() id:heleeen です。
id:heleeen です。
この記事は、はてなの SRE が毎月交代で書いている SRE 連載の4月号で、先月分は ![]() id:taxintt さんのサービスの一般公開前からSLI/SLOと向き合うです。
id:taxintt さんのサービスの一般公開前からSLI/SLOと向き合うです。
今回は、先日 Mackerel チームで行った障害対応演習で実施した内容と、どのような学びを得たかについて紹介します。
本番障害はできればなくしたいものですが、すべての障害を完全になくし可用性を100%にするのはとても困難です。そのため、障害が発生したときの影響範囲を小さくする仕組みを導入したり、ロールバックを素早く行えるようにしておくなど、影響を抑えるための取り組みが必要になります。
Mackerel では、その一環として、障害対応時のオペレーションの確認やバックアップからの復旧が行えるかの検証などの起きてしまった障害を素早く収束させたり、障害対応への心理的なハードルをさげたりするための訓練を行っています。
先日行った障害対応演習が、演習の準備をしたわたしにとっても予想外の結末になり、期待を超えた学びを得られたので共有します。
障害対応演習とは
Mackerel では年に2回の障害対応演習を行っています。そのときによって演習の内容は異なりますが、基本的なオペレーションの手順が実施できることの確認と、実際に手を動かして障害調査と復旧を行う演習の2つをテーマに行うことが多いです。
基本的なオペレーションの確認では、バックアップからの復元やフェイルオーバー、再デプロイなど、固定の手順のオペレーションが問題なく動作する状況であるかを、実際に手順を実行しながら確認しています。日常的に行わないオペレーションもあるため、必要になったときに焦らずに済むように定期的な確認や実行した経験を持つことが目的です。
手を動かす演習としては、本番ではない環境で意図的に障害を発生させ、障害対応のフォーメーションを組んで調査と対応を行っています。演習で扱う障害の内容は、最近発生した障害やアーキテクチャの変更があった箇所などを参考にしたり、クラウドでの障害調査を実践したりするものを選択しています。
年2回実施しているのはAWS コンピテンシープログラムなどの都合もありますが、新しく入社した方が障害対応にふれる機会をなるべく早く持てるようにすることと、繰り返すことで定着させることが主な狙いです。加えて、アーキテクチャの変更に追従できていないドキュメントの修正点を速めに見つけることや、演習内容の準備と学習の負荷分散も考慮しています。
そのほか障害対応演習の設計で考慮していることについての詳細は、先日のエンジニアセミナーをご覧ください。
先日行った演習では、基本的なオペレーションの確認として Amazon ElastiCache のリストア、手を動かす演習として障害対応フローのロールプレイ、検証用の環境での障害対応の実施を行いました。
基本的なオペレーションの確認
障害対応で行われるオペレーションには、リストアやロールバック、再デプロイなど固定の手順があります。このうちリストアは、復旧手順を再確認するとともに、日頃取得しているバックアップは本当にバックアップとして利用可能なものかの確認も行う必要があります。
今回は ElastiCache をバックアップから復元し、アプリケーションからの参照を差し替えることで本当にリストアが成功するかを確認しました。この ElastiCache を参照するアプリケーションや監視用のツールがいくつかあり、それぞれに対するリリースフローの再確認やどこでこの ElastiCache を利用しているかの再確認にもなってよかったです。
この他にもリストアを検証したいものはいくつかあるのですが、ここでは ElastiCache のみを選択しました。年2回の演習でリストアの検証を行う対象を分散させつつ、手を動かす演習のほうでも別のデータストアのリストアの検証を含むことにしたため、ここでは一部のリストアの検証のみを行うことにしました。
障害対応フローのロールプレイ
実際の障害対応では、障害対応に慣れている人やシステムを理解している人の動きが迅速であるため、どのように判断して動き出しているか、何を調査すればよいかを障害対応の場で学ぶのが難しい場合が多いです。そこで、障害対応の初動や対応の方針を決めるときに、どのような方針で対応を進めるか、障害の調査にあたって何から調査するかを実際のシステムを利用して確認していきました。

障害対応の考え方を再確認した後に、ロールプレイ形式での演習を行いました。障害を発生させず、ある障害が発生したと仮定して障害対応フローのロールプレイを行うものです。
はてなの障害対応では、対応の記録を行うためのテンプレートを用意しており、演習でもそのテンプレートを利用しています。ロールプレイ形式の演習では、障害対応の方法より障害対応フローやテンプレートの中身の習得と改善に集中して実施できました。障害対応テンプレートも改善されていくものなので、変更点のキャッチアップの場にもなってよかったです。
また、はてなでは、新しく入社された方が障害対応の基本的な流れを学ぶための研修があります。ロールプレイを通して障害対応の基本的な流れを理解し、チーム配属後に障害対応に参加できるようになることを目指して作成したものです。今回実施したロールプレイの演習は、この研修を参考に作成したものでした。
この研修は今年から入社された方に向けて作成したものなので、これまで入社した人がこの研修を受ける機会がないことになります。昨年までに入社した人は基本的に障害対応や障害対応演習を経験しているので、このロールプレイがどれほどの効果があるかは気になっていましたが、この演習の後に発生した障害対応の初動がとてもスムーズでした。チーム内でも障害対応への慣れや理解には個人差があり、スムーズに障害対応を始めるには初動と基礎を確認することが効果的だったと考えています。
検証用の環境での実践
ここまで学んだことを実践する場として、検証用の環境で障害を発生させての対応も演習しました。これは座学のみではなく、実際に障害対応を経験してみることを目的にしています。また、オペレーションの確認やロールプレイと障害の内容を別にすることで、対応したことのある障害内容の種類を増やす狙いもあります。
検証用の環境を利用した演習ではありますが、本番相当に対応するというルールで演習を行なっています。そのため、必要であればユーザーへの告知の文章を用意したり、ディレクターに状況を共有したり、サービスをメンテナンス状態にしたりすることも期待していました。また、この演習ではアプリケーションエンジニアが手を動かすことを目的としたため、SRE は障害の対応ではなく、調査や対応に困っていそうなときのサポートを行います。
今回は、検証後に不要になった RDS インスタンスを削除するつもりが、間違えてサービスで利用している RDS インスタンスを消してしまうというオペレーションミスを障害原因としました。わたしが PostgreSQL の検証で RDS インスタンスを構築したり削除したりを繰り返す中で、いつか自分がオペレーションミスを起こして消してはいけないものをうっかり消してしまうかもしれないという危機感を持っていたことから着想を得た障害内容です。これまでも年に数回検証する機会があったため発生させる可能性はゼロではなく、万が一そうなってしまった場合に復旧するための練習をしておきたい気持ちがありました。

バックアップからのリストアは、基本的なオペレーションの確認として過去の演習で実施している内容ではあるため、スムーズに実施できる人もいると考えていました。そのため今回は、復旧手順に加えて障害対応フローに慣れた人を増やすことを目的にしました。具体的には、比較的チーム歴の浅い人を優先して指揮官などの役割を担ってもらうことや、対応にあたる人数が多くなるような障害を題材とするなどです。普段はただのオペレーションの確認として行っていたことが実際に必要となるのは、本物の障害らしさがありますね。
検証用の環境で稼働中のアプリケーションが参照する RDS インスタンスを削除したので、定期バックアップからリストアして復旧するという演習を想定していました。しかし、データベースを削除するときに、誤って定期バックアップもすべて削除してしまったため、普段練習している手順では復旧できないことが判明し、状況が一変しました。RDS インスタンスを削除する際にバックアップを保持するオプションを有効にする必要があったのですが、それを見逃して定期バックアップをすべて削除してしまいました。
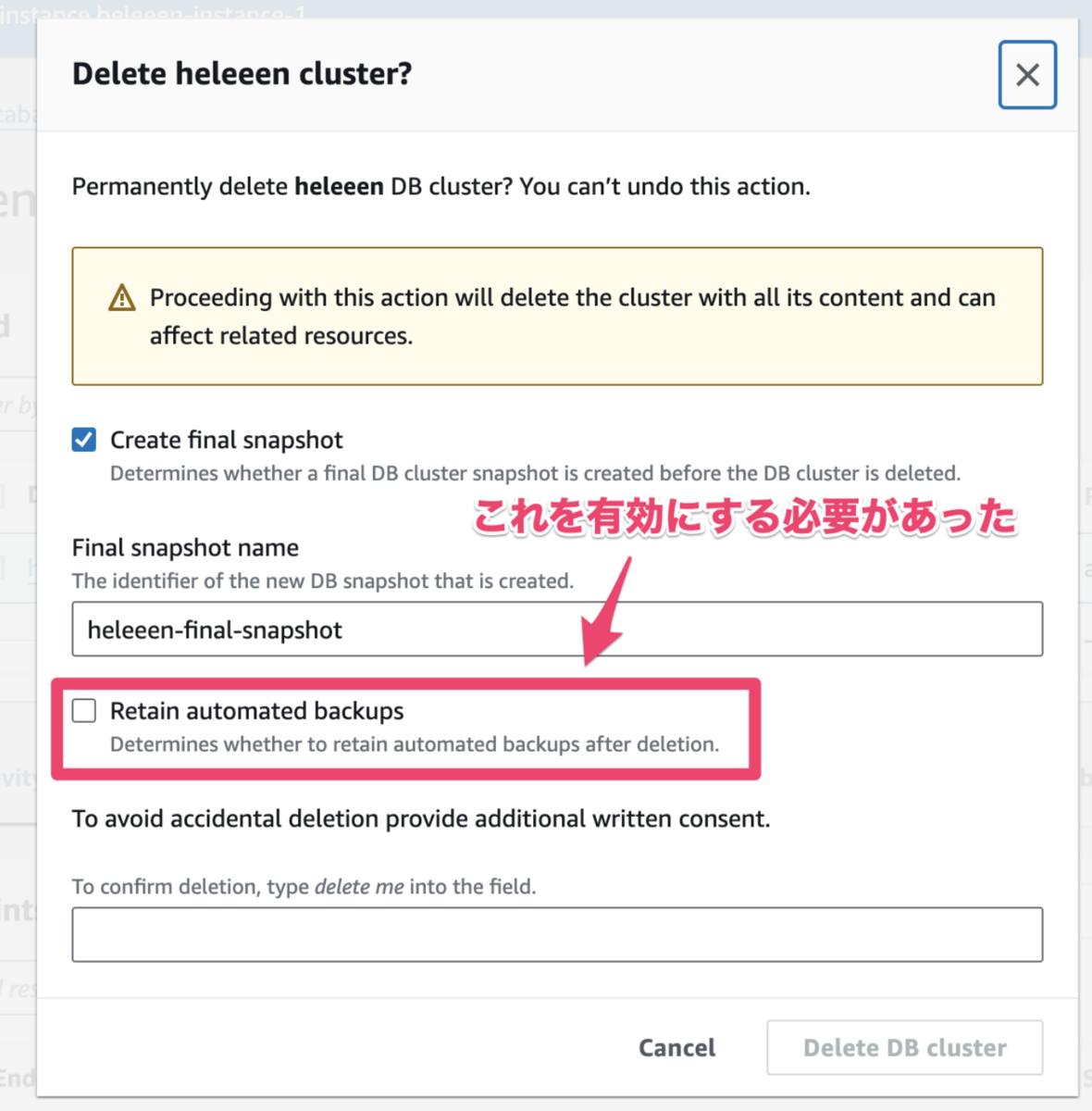
この設定では手動で作成したスナップショットは削除されないため、偶然少し前に別の検証のために手動で作成していたスナップショットに戻すことは可能でした。しかし、それは定期バックアップより更に古いものなので、アプリケーションと整合性を取るために DB マイグレーションが必要になるなど、テーブルが結構古い状態になったときにシステム的に必要な手順を実施する必要があります。また、長期間のデータが消失することがビジネス的にどのような影響があるかを考慮する必要がありました。演習なので、これはどのような影響がシステムとして出ているかを整理し、ビジネスチームへ連絡する練習までを行いました。
今後の対策として、削除時にチェックボックスを1つ有効にすることや最終スナップショットを取得することをルールにしてもオペレーションミスはなくせないため、より安全にバックアップを取得し管理する方法としてバックアップを別のところに保存するなどの目的で AWS Backup を検証しています。
予定では障害対応自体は2時間もかからない見込みでいたのですが、3時間を超える障害対応となりました。長時間の障害対応になる場合は、疲労しすぎないように指揮官や書記を交代すべきという学びが得られたのもよかったです。これは引き継ぎの練習になったり、役割を担った経験がある人を増やしたりする効果がありそうと思っています。
まとめ
障害対応演習として一般的なオペレーションの確認だけではなく、障害対応のフローを実施し、手を動かすことはとても学びが多いです。特に、実際に障害対応を行っておくことは、手順の把握とともに経験を積んだことにより障害対応への心理的なハードルが下がるという効果も感じました。個人的には、重い障害でも復旧できることに安心感も得られましたが、二度とこの障害を体験しなくて済むように、今後のオペレーションに一層の緊張感を持って望むようになったり、より安全な方法が必要とわかったりしたのもよかったです。