はてなブログでSREをやっている![]() id:cohalzです。
id:cohalzです。
2019年12月頃から![]() id:utgwkkや
id:utgwkkや![]() id:onkとともに、はてなブログにおけるキャッシュ周りの改善を行いました。その結果、次のような成果が得られました。
id:onkとともに、はてなブログにおけるキャッシュ周りの改善を行いました。その結果、次のような成果が得られました。
- ブログ記事のキャッシュヒット率が、1日平均で8%から58%に向上
- アプリケーションサーバの台数を、以前の半数以下に削減
- DBに届くリクエスト数が、以前の3分の2まで減少
- レスポンスタイムの平均が、以前の8割まで減少
この記事では、実際にどういった改善を行ったのか、その際に気をつけたことや大変だったことを紹介します。
- はてなブログがVarnishを導入した経緯と課題
- ホストのメモリをできるだけたくさん利用する
- キャッシュが分散しないようVaryヘッダを使う
- 効果を見つつキャッシュのヒット率を改善
- そのほかのキャッシュの改善
- はてなブログのキャッシュのこれから
はてなブログがVarnishを導入した経緯と課題
はてなブログでは2016年に、より多くのトラフィックに耐えられるようリバースプロキシとアプリケーションの間にVarnishを導入しました。
しかし、導入したきっかけは「バーストに耐えられるようにする」ことでそれ以上はできず、最低限のキャッシュしかできていませんでした。
そういった事情からアプリケーションサーバの台数もかなり多く、DBへのアクセスも多いため、レイテンシやコスト面から見てもかなり改善の余地がある状態でした。とは言ってもパフォーマンスでひどく困っているわけでもなく、改善は後回しにされていました。
開発合宿をきっかけに問題が明らかになる
はてなには、開発合宿というイベントがあります。有志で募ったメンバーが普段の開発から離れ、テーマを決めて取り組む機会になります。
2019年12月に行われた開発合宿で、前述した2人と「はてなブログのパフォーマンス改善」をテーマに、3日間集中して取り組みました。
そこで分かったのは、記事のキャッシュヒット率が8%程度しかなく、メモリ使用量も次の図のように日中は頭打ちになっているということでした。ここから、キャッシュ周りを継続して改善する必要があると判断しました。

進め方をまず考える
キャッシュ周りが改善できると、パフォーマンスにも大きなメリットが出ます。しかし、気をつけないと正しくないレスポンスを返してしまったり、ページが更新されなくなってしまう可能性もあります。
安全に進めるため、上記のメンバーにテックリードも含めた定例会を設けて、作戦を決めたり、リリースした変更の効果を確認しながら進めました。
不具合が発生したときにもできるだけ早く気付けるように、ユーザーからの問い合わせに対応するサポートメンバーにも変更予定を共有し、何かしら関係しそうな問い合わせがあったらすぐ内容を伝えてもらえるようお願いしました。
ホストのメモリをできるだけたくさん利用する
Varnishでは、キャッシュをすべてメモリに持ちます。搭載しているメモリをできるだけ利用できる(かつOOM Killerが発生しない)よう、どれだけ使えるのか調べました。結論から言うと、公式ブログの記事にあるとおり「ホストで使えるメモリ量の75%まで」です。

また、Varnishでは通常のオブジェクトを格納するものとは別に、Transientと呼ばれるストレージが存在し(下記参照)、これも同じくメモリを使います。その分の容量も用意し、キャッシュに使う分と合わせて75%になるよう設定する必要がありました。
▶ Varnish3で多くのオブジェクトを持つサイトを運営するときに注意するべきたった一つのこと(Transient storage) – cat /dev/random > /dev/null &
それでは、Transientストレージにどの程度のメモリを用意しておくべきでしょうか。その判断の材料とするため、MackerelでTransientストレージ関連のメトリックを取れるように、mackerel-plugin-varnishを修正しました。
このメトリックをもとに、メモリ容量を適切に配分できるようになりました。
メモリを積んだホストでなぜかレイテンシが悪化
メモリを配分する際、キャッシュに使えるメモリが十分にないということで、メモリをたくさん積んだホストを新規に投入してみました。しかし、追加したホストのCPU使用率が日に日に上がり続け、結果としてレイテンシが悪化していました。

これでは困るので新規ホストの投入は後にして、既存のホストを使い続けながら原因究明に当たりました。結論としてはVCL(Varnish Configuration Language)が、キャッシュを削除する箇所でずっと非推奨の書き方になっていたためでした。
Varnishのキャッシュ削除にbanによる削除を使い、条件にreq変数を使ってしまった場合、本来は別スレッドでも実行できるキャッシュ削除が処理されなくなり、リクエストを処理するスレッドでしかキャッシュを削除できなくなるため、レイテンシおよびCPU使用率に悪影響が出ていたのです。
新しく追加したホストだけでパフォーマンスが悪化したのは、メモリにたくさんのキャッシュが載るようになった結果、TTLが長いキャッシュがメモリにどんどん積まれ、破棄にかかる時間も少しずつ延びていったためでした。以前のホストではメモリが少なすぎて十分にキャッシュできておらず、逆に問題が起きなかったのです。
公式ドキュメントにも、以下のように書かれています。
Bans that are older than the oldest objects in the cache are discarded without evaluation. If you have a lot of objects with long TTL, that are seldom accessed, you might accumulate a lot of bans. This might impact CPU usage and thereby performance.
公式の参考書『The Varnish Book』の「Lurker-Friendly Bans」に従ってVCLを書き直したところ、パフォーマンスの問題もなくなり、メモリをたくさん載せたホストを利用できるようになりました。
キャッシュが分散しないようVaryヘッダを使う
それまで、はてなブログではVaryヘッダにUser-Agentを指定していました。そのため同じページを開いても、ブラウザのバージョンが微妙に違っていたら同じキャッシュを使えていませんでした。
はてなブログでは、閲覧しているデバイスがPCかスマートフォンかでコンテンツを出し分けています。このためキャッシュもユーザーエージェントごとではなく、PC版かスマートフォン版かの2種類のみにできるようにしました。
具体的には、Varnishの前段にあるリバースプロキシ(nginx)でデバイスを判定し、独自のリクエストヘッダとして追加してVarnishに渡します。この独自ヘッダをアプリケーションでVaryに指定すれば、Varnishは渡されたデバイス情報別にコンテンツをキャッシュします。
デバイス情報を適切に判定する
リバースプロキシでは、User-AgentヘッダからPCかスマートフォンかを判定することになりますが、間違えると別の版が配信されてしまいますし、特定のユーザーエージェントに対して特別な処理をしていた場合にはその挙動も変わってしまうため、注意が必要でした。
最初はMobileという文字が含まれているかどうかで判別しようとしましたが、これでは不十分でした。はてなブログでは以前からiPadにはPC版を表示しており、iPad OSでは正しく判別できましたが、iOS 12以前ではiPadでも必ずMobileが入っていてスマートフォン版が出てしまいました。
そこで方針を一部変更し、iOS 12以前でもiPadならiPadという文字列が含まれていることを利用して、最終的には以下の優先度で判別することにしました。
iPadが含まれている → PC版Mobileが含まれている → スマートフォン版- それ以外 → PC版
これでキャッシュの単位がPC/スマートフォンの2種類になりましたが、PCとスマートフォンで区別する必要のないエンドポイントもいくつかありました。フィードやAMPページなどです。同一の内容が無駄に2つキャッシュされてしまうため、分散しないよう対処する必要がありました。
そこでエンドポイントごとにPC版とスマートフォン版のレスポンスを比較し、同一であったページに対しては、デバイス情報の独自ヘッダそのものをVaryに含めないようにしました。
効果を見つつキャッシュのヒット率を改善
これでVarnishの環境は整いましたが、当初はキャッシュの有効期限が1分だったり、一部のエンドポイントしかキャッシュできていなかったりという問題がありました。
そこでヒット率が悪いエンドポイントや、ヒットミスでレスポンス時間に大きく差が出てくるエンドポイントを優先的に、より多くのエンドポイントでキャッシュから長期間にわたって返せるよう改善を進めました。
改善にあたっては、主にCPUやメモリ、リクエスト数といったものを中心にどのような影響が出たのかを確認するため、Mackerelを活用しました。とくに複数のメトリックを元に新しくグラフを表示できるので、DBへのリクエスト数を1日前や1週間前と比較したグラフなどを用意して効果を確認しました。

さらに、mackerel-plugin-varnishで取得できるヒット数などのメトリックを使って、そのときのキャッシュヒット率をすぐに確認できるようにもしました。

ほかにはAmazon S3に保存されていたアクセスログを、エンドポイントとキャッシュヒットしたかどうかでグルーピングしてAmazon Athenaで集計し、Googleデータポータルで可視化しました。


どのエンドポイントから改善するかを考えつつ、有効期限を少しずつ伸ばしたり、キャッシュするエンドポイントを増やすなどして、最終的に多くのエンドポイントでキャッシュの有効期限を1日まで伸ばすことができました。
クエリ文字列を正規化してキャッシュの分散を防ぐ
VarnishでキャッシュするキーにURLを含めていたため、同じパスでもクエリ文字列が異なる場合には、違うキャッシュとして分散していました。これを、できる限り同じキャッシュから返すように変更しました。
まず、アプリケーションでさまざまなクエリ文字列を参照していることは分かっているため「使われているものを列挙して、載っていないものはすべて同じキャッシュを使う」という手法は現実的ではないと判断しました。
そこでVarnishのvmod-querystringモジュールを使ってクエリ文字列をソートしつつ、特定のキーのみに同じキャッシュを使う作戦を取りました。それでは、どのキーなら同じキャッシュを使ってよいのでしょう。
アクセスログをAthenaで処理し、たくさん使われている順にクエリ文字列のキーを集計しました。集計結果の上位からいくつか、アプリケーションで参照されていないクエリ文字列かどうかを実装に当たって1つ1つ確認し、キャッシュが分散しないようにしました。
最終的に、_gaやutm_source、__twitter_impressionなどのクエリ文字列を正規化しました。
圧縮してからキャッシュしてメモリや転送量を節約
キャッシュの有効期限を伸ばしたことで、メモリに載るキャッシュの数も増えてきました。このためメモリが足りなくなることがあり、ホストの台数を随時増やしていました。しかし、あまり増やし続けても費用が大きくなってしまうため、新しいアプローチを考える必要がありました。
Varnishには、gzip圧縮した状態でメモリにキャッシュする機能があり、これを使いはじめました。はてなブログは、前述したようにVarnishがnginxの後段にある構成です。以下を参考に、圧縮済みのレスポンスをnginx側で返す設定にしました。


この記事にもあるように、圧縮済みのファイルをnginxで返す際には、gzipに非対応(Accept-Encoding: gzipではない)クライアントにも正しくレスポンスを返せるよう気をつける必要があります。
最終的に、Varnishとnginxで以下のような動きをするように設定しました。
- Varnish ... すべてのレスポンスをgzip圧縮してキャッシュする
- nginx ... レスポンスを、クライアントのAccept-Encodingによって決める
Accept-Encoding: gzipである → そのまま圧縮されたレスポンスを返すAccept-Encoding: gzipでない → その場で展開してレスポンスを返す
結果として、以前より約3倍のキャッシュを保持できるようになり、メモリにも余裕が生まれました。
さらに予想していなかった効果として、これまでAccept-Encoding: gzipのときにはnginxで毎回圧縮していましたが、これがなくなったことによりレイテンシや、nginxのCPU使用率などが改善されました。
また、nginxとVarnishの間で転送されるデータ量も少なくなり、AZ間通信の転送料も大きく削減できました。 一方、Varnishのホストで圧縮コストがかかりますが、リクエストごとでもなく、もともとCPUリソースには余裕があったため、特に問題にはなりませんでした。
そのほかのキャッシュの改善
ここまで紹介したVarnishを中心とする改善のほかにも、キャッシュやコンテンツ配信の効率化についていくつか改善を行っています。
memcachedにもキャッシュしていたのをやめた
はてなブログでは、Varnishだけではなくmemcachedにもキャッシュを保存しており、Varnishでヒットしなかった場合でもDBへのリクエスト数を減らすメリットがありました。
しかし、複数箇所でキャッシュする分、更新時に正しく抜けもれなくすべて破棄するのが難しくなったり、memcachedにも大量のメモリが必要になったりして、効率もあまりよくなかったため廃止することにしました。
とはいえ、いきなりmemcachedを使わなくすると、DBへのリクエスト数が急に増えてしまう可能性があったため、カナリアリリースの手法を取って、少しずつ使わなくしました。
具体的にはアプリケーションの管理画面で、memcachedをどのくらい使わないか設定できるようにしました。エンジニアがいつでも変更できるので、リリース&ロールバックのタイミングとは関係なく、問題があればすぐ切り戻しできます。

様子を見ながら使わない割合を上げていき、一切使わなくなっても負荷に問題ないことが確認できたため、memcachedへの保存をやめることができました。
その結果、キャッシュする箇所を一本化できただけでなく、memcachedのみにキャッシュしていたエンドポイントのヒット率が向上したり、memcachedのホストの台数が削減できたりなどの効果もありました。
少しだけ動的なファイルをngx_mrubyから配信する
リクエストが多いのに、まったくキャッシュできていないエンドポイントがありました。robots.txtを配信している箇所です。
このファイルにアクセスするのは基本的にGoogleなどのクローラであり、特別に重いエンドポイントでもないため、Varnishでキャッシュする優先度は高くありません。また、メモリが足りないときにrobots.txtをキャッシュした場合に、代わりに重い部分のキャッシュがメモリから追い出されてしまうのは避けたいという事情もありました。
とはいえ、アプリケーションサーバにまったくキャッシュされていないリクエストが届いてworkerプロセスを専有してしまうことから、アプリケーションからレスポンスを返すのをどうにかやめられないか検討しました。
User-agent: * Sitemap: https://developer.hatenastaff.com/sitemap_index.xml Disallow: /api/ Disallow: /draft/ Disallow: /preview User-agent: Mediapartners-Google Disallow: /draft/ Disallow: /preview
robots.txtは上記のようなファイルで、Sitemapのドメインはブログごとに異なりますが、その他の部分はどれもすべて同じでした。ほとんど静的ファイルのようなものですが、Sitemapだけどうにかして動的に生成するような工夫が必要でした。


上記の記事にもあるように、はてなブログでは独自ドメインをHTTPS化する際に、ngx_mrubyを利用するようにしていました。これを用いてrobots.txtを返すことができるかもしれません。ngx_mrubyを使うのは初めてでしたが、docsも充実していたため、コードはすぐに完成しました。
r = Nginx::Request.new scheme = r.var.http_x_forwarded_proto || r.var.scheme host = r.var.http_x_forwarded_host || r.var.host ROBOTS_TXT = <<EOS User-agent: * Sitemap: #{scheme}://#{host}/sitemap_index.xml Disallow: /api/ Disallow: /draft/ Disallow: /preview User-agent: Mediapartners-Google Disallow: /draft/ Disallow: /preview EOS r.content_type = "text/plain" Nginx.rputs ROBOTS_TXT
とはいえ、ngx_mrubyを使って直接ユーザーにレスポンスを返した例はまだなく、安定してrobots.txtを配信できるのか不安もありました。そこで、アプリケーションから返すバージョンと、ngx_mrubyから返すバージョンで、それぞれ本番のリクエスト数を模して負荷検証を行いました。

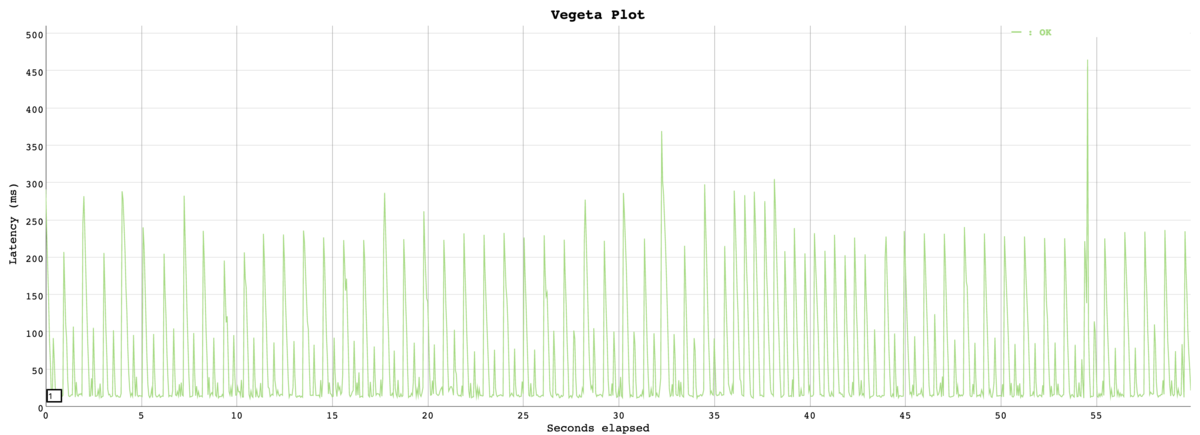
その結果、ngx_mruby版の方がむしろレイテンシもよく、エラーも返すことはないことを確認できたため、ngx_mruby版に置き換えました。
デザインCSSをCDNから配信する
Varnish周りの改善から多くの記事がキャッシュできるようになりましたが、本当に「アプリケーション・DBの障害時にも、キャッシュから記事を閲覧できるのか?」に関しては不明でした。
そこで開発環境において、Varnishにキャッシュを載せた状態でDBやアプリケーションを実際に停止し、挙動を確認しました。その結果、記事のHTMLはキャッシュから返せているものの、ブログのテーマなどを含むデザインCSSが配信できないことがわかりました。
それまでデザインCSSはブラウザキャッシュのみで、これを機にVarnishでキャッシュしてもよかったのですが、CDN(Akamai)を使うことにしました。
デザインCSSはデザイン変更時にURLも変わる設計になっていることもあり、キャッシュのことをあまり考えなくてよく、CDNに載せやすい状態だったためです。また、既に一部のレスポンスをCDNでキャッシュしはじめていたこともあります。
とはいえ、非公開ブログのコンテンツについては、どのように扱うか考える必要があります。結論として、公開ブログのデザインCSSを配信するドメインを新設し、以下の仕様になりました。
- 公開ブログのデザインCSS ... 新設したドメインからCDNを通して配信する
- 非公開ブログのデザインCSS ... 既存のドメインから従来どおり配信する(キャッシュなし)
- 公開ブログを非公開にした場合、CDNにあるキャッシュを即時破棄する
はてなブログのキャッシュのこれから
このような改善により、以前と比べてキャッシュから返せるリクエストはかなり増えました。しかし、まだまだVarnishでキャッシュできていないエンドポイントも多く、継続的に改善していく予定です。
また、現状ではデプロイ時にすべてのキャッシュを破棄しているため、そのタイミングでアプリケーションの負荷が高まってしまう課題があり、これをどのように解決するかも考える必要があります。
さらにVarnishだけでなく、CDNやngx_mrubyなどももっと活用して、さらにパフォーマンス・対障害性に優れたアーキテクチャを目指していきたいと思っています。