この記事は、はてなエンジニア Advent Calendar 2023の2024年1月17日の記事です。
![]() id:hagihala です。先日、はてなブログの DB を RDS for MySQL 5.7 から 8.0 へアップグレードしたので、工夫した点などを共有します。
id:hagihala です。先日、はてなブログの DB を RDS for MySQL 5.7 から 8.0 へアップグレードしたので、工夫した点などを共有します。
- Aurora MySQL 3.x にしなかった理由
- MySQL 5.7 -> 8.0 で対応した変更点
- インスタンスサイズ縮小のためにやったこと
- 負荷試験
- readonly メンテナンス
- アップグレード後に出た不具合
- ふりかえり、感想
Aurora MySQL 3.x にしなかった理由
RDS for MySQL 5.7 からのアップグレード・移転先としては Aurora MySQL 3.x も有力な候補に挙がります。 すでに社内で採用しているサービスもあり、最終的に Aurora に移行する計画ではあるので Aurora 3.x へ一気に上げてしまうことも検討しましたが、今回は見送ることにしました。
MySQL 8.0 へのアップグレード + Aurora への移行をまとめて行う事で準備やメンテナンスの回数を減らせるメリットと、不具合の発生する可能性が上がる、問題発生時の切り分けが困難になるなどのリスクとのトレードオフで後者の方が勝ったためであり、 Aurora 自体に何かしら問題があったという訳ではありません。 また、今回アップグレードした DB は I/O intensive なため以前は I/O 課金が高額になる可能性が高く躊躇していましたが、2023年5月に Aurora I/O Optimized がリリースされたことで解消されています。
MySQL 5.7 -> 8.0 で対応した変更点
網羅的な変更点については公式ドキュメントや他の情報源が既にたくさんあるので、はてなブログで直面した・対応した変更点について説明します。
MySQL :: MySQL 8.0 Reference Manual :: 2.10.4 Changes in MySQL 8.0
character set や collation のデフォルトが変更される
character_set_server及びcharacter_set_databaseシステム変数のデフォルトがlatin1からutf8mb4に変更collation_server及びcollation_databaseのシステム変数のデフォルトがlatin1_swedish_ciからutf8mb4_0900_ai_ciに変更
はてなブログでは utf8mb4 については以前から設定していたので問題ないのですが、 charset が utf8mb4 の場合のデフォルトの collation が utf8mb4_general_ci から utf8mb4_0900_as_ci に変わるので、テーブルの作成時にスキーマに明記していないと utf8mb4_0900_as_ci になってしまいます。
パラメータグループに collation_server = 'utf8mb4_general_ci' を明記しました。
また、開発環境やテスト環境などで使用するときに備え、スキーマにも charset と collation を明記しました。
こちらのエントリが参考になります。 MySQL 8.0 でも utf8mb4_general_ci を使い続けたい僕らは - mita2 database life
explicit_defaults_for_timestamp がデフォルトで有効になる
これを有効にすることで、 TIMESTAMP カラムのデフォルト値や NULL 値の扱いが、これまでは NULLがアサインされた場合に自動で現在日時をセットするといった非標準な (緩い) 動作だったのが、標準的な動作になります。
MySQL :: MySQL 8.0 Reference Manual :: 5.1.8 Server System Variables #sysvar_explicit_defaults_for_timestam に詳しい条件が書かれていますが、最終的な動作には SQL mode NO_ZERO_DATE なども影響してきます。
ざっくりと説明すると、 TIMESTAMP カラムの宣言時に明示的に NOT NULL attribute を付けなければ NULL 値を許容するようになり、またカラムに NULL をアサインした際に自動で現在日時をセットするといった暗黙的な動作を行わなくなります。
NOT NULL なカラムに NULL をアサインした際の動作はカラムの DEFAULT の設定や SQL mode によっても変わるようですが、 strict モードの場合は暗黙的なデフォルト値がセットされる事を期待した操作はエラーになるようです。
SQL mode の変更
システム変数やパラメータグループのデフォルト値は以下のように変わります。
- 5.7:
NO_ENGINE_SUBSTITUTION - 8.0:
ONLY_FULL_GROUP_BY STRICT_TRANS_TABLES NO_ZERO_IN_DATE NO_ZERO_DATE ERROR_FOR_DIVISION_BY_ZERO NO_ENGINE_SUBSTITUTION- ただし RDS のパラメータグループのデフォルト値は
NO_ENGINE_SUBSTITUTIONのまま (5.7 と同じ)
- ただし RDS のパラメータグループのデフォルト値は
はてなにおいては以前からいわゆる kamipo TRADITIONAL を使うことが推奨されているのですが、はてなブログでは変更にかけるリソースが割けなかった (伝聞) 事により、5.7 のデフォルトが使われています。
また、SQL mode の設定はアプリケーション側で持つべきとの考え方から、アプリケーションの DB 接続時にセッション単位で sql_mode をセットするようになっています。
SET SESSION sql_mode='NO_ENGINE_SUBSTITUTION'
今回のアップグレードでは以下のようにしました。
- パラメータグループ (グローバル変数) には MySQL 8.0 のデフォルトを指定する
- アプリケーションがセットするセッション変数はアップグレードのタイミングでは変更しない
アプリケーション側は SQL mode 変更のための修正に工数を割くよりアップグレードを優先するため、これまで通りセッション単位で 5.7 のデフォルトを指定することにしました。
一方で 8.0 のデフォルトは kamipo TRADITIONAL と同程度に厳格なので、パラメータグループは 8.0 のデフォルトにしました。
人間または別のプログラムによるクエリ実行は基本的にイレギュラーな操作なので厳格にいきたいという意図で、緩める必要がある場合はアプリケーションと同様に明示的にセッション単位で SQL mode を指定しましょうという運用です。
デフォルトの認証プラグインが caching_sha2_password になり、 mysql_native_password が Deprecated
MySQL 8.0 ではデフォルトの認証プラグインが mysql_native_password から caching_sha2_password に変更されます。
ただ、すべてのクライアント側が対応している必要があることなどから今回は mysql_native_password のままにしています。
ちなみに RDS パラメータグループの default_authentication_plugin は mysql_native_password に固定されており変更できません。
10000-01-01 や 9999-99-99 といった日付の含まれるクエリがエラーになる
10000-01-01 や 9999-99-99 のような不正な日付は DB の DATETIME 型のカラムには格納できませんが、クエリに含める分には MySQL 5.7 では (warning が出るものの) 可能となっています。一方で MySQL 8.0 (8.0.16 以降) 環境ではこれらのクエリが即エラーになるようです。
8.0 の変更点には書かれていなかったため謎でしたが、 8.0.16 で変更されたものであり、従来の挙動がバグである (という扱いになっている) ことが分かりました。
まず、MySQL 8.0.15 以下では文字列と DATE 型を比較する場合、以下の手順を踏む。 1. 文字列を DATE (or DATETIME) に変換して比較する 2. 1.の変換ができない場合は逆に DATE を文字列に変換して比較する
これが MySQL 8.0.16 以上では次のような手順に変更された。 1. 文字列を DATE (or DATETIME) に変換して比較する 2. 1.が失敗した段階でエラーとなる
MySQL 8.0.15 の前後で変わった文字列と DATE 型の比較について - それが僕には楽しかったんです。
文字列比較は辞書順での比較になるため、10000-01-01 < 2024-01-17 が true になるなど、エラーにはならなくても意図通りに動いていなかったことになります。
invalid な日時がクエリに含まれないよう修正する事で対処しました。
インスタンスサイズ縮小のためにやったこと
今回のアップグレード対象 DB では過去にデータ移行のために DB のインスタンスサイズを大きめにしており、現状の負荷に対してオーバースペック気味になっていました。
そのためアップグレードと併せてインスタンスタイプを縮小することを検討しました。
変更後のインスタンスタイプが本番の負荷に耐えられるかどうかは後の負荷試験でも確認するつもりではあったものの、本番と同等の負荷を精確に再現することは難しいので、本番環境で試すに越したことはありません。
MySQL 5.7.5 以降では innodb_buffer_pool_size の動的な変更ができるので、事前に本番環境で innodb_buffer_pool_size を変更後のインスタンスタイプ相当のサイズに縮小し、 (あくまで 5.7 環境ではあるものの) ストレージ I/O の上昇やアプリケーションのレイテンシの悪化が許容範囲内に収まる事を確認しました。
RDS ではこの変数を RDS のパラメータグループ経由で変更する事になるため、 パラメータグループの変更 API を叩いてから実際に MySQL へ反映されるまでに多少のラグがあります。なので API 実行後に SHOW STATUS WHERE Variable_name='InnoDB_buffer_pool_resize_status' を実行して変更のステータスを確認し、完了するのを待ってから次の変更を行う必要があり、やや時間のかかる操作になります。
変更が適用される際にクエリが一時的にブロックされるなどの影響があるため、一度に減らす量を大きくしすぎるとサービスのレイテンシが悪化したり処理がタイムアウトしたりする可能性があります。今回はサービスへの影響を見ながら1回あたりの変更サイズを決め、最終的に4GB刻みで徐々に減らしていき、変更予定インスタンスサイズ相当のバッファプールサイズでもパフォーマンスに大きな影響が出ない事を確認しました。
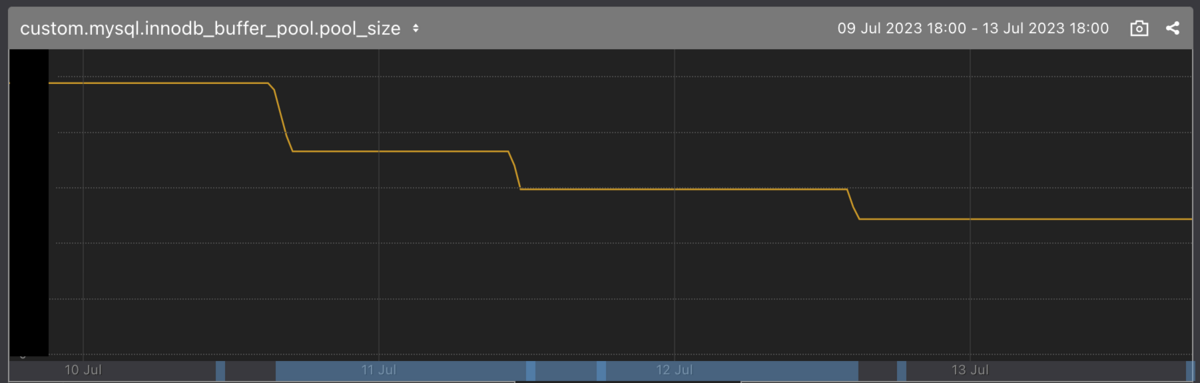
後で見返したときに作業していたことが分かるよう Mackerel のグラフアノテーション (グラフ下部の青い帯) を付けてあります。 ちなみに短い帯はデプロイの記録です
負荷試験
負荷試験に使うクエリは、本番環境の general log を一定期間分出力したものから SELECT クエリのみを抽出して用意しました。サービスの性質上 read の割合が圧倒的に高いため更新クエリについては負荷試験を省略しました。 当初は他チームの事例に倣い、 general log を CloudWatch Logs に流す設定を有効にし、 データを S3 にエクスポートして取得していたのですが、今回のアップグレード対象DBでは上手く行かないことが分かりました。
- サイズの大きなクエリが含まれるため CloudWatch Logs のログイベントのサイズ上限 (256KB) に当たって分割されてしまう
- 元々 CloudWatch Logs ではログイベントの順序が保証されないのに加え、分割されたログイベントには結合に使うためのメタデータ等が付与されないため元のクエリを完全に復元する方法が無い
今回はそもそも CloudWatch Logs を経由しなくても、インスタンス上に出力された general log を Web コンソールからダウンロードボタンをポチポチすれば普通にダウンロードできるため、そうすることにしました。
今回はそれで事足りましたが、「クエリをリアルタイムに抽出してミラーリングし続ける」みたいな事をやる場合は DownloadDBLogFilePortion API を用いてログローテーションを考慮しながら取得し続けるような処理を自前で用意する必要がありそうです。
負荷試験の実施には、与えられた並列度の組に対して定められた回数実行し、結果をカンマ区切り (Google スプレッドシートに貼り付け可能な形) で出力するスクリプトを用いました。
#!/bin/bash
# ./run.sh <QUERIES_FOR_TEST> <HOST> <DATABASE> <CONCURRENCY1>,<CONCURRENCY2>,... <NUM_TRIALS>
set -eu
SQL=$1
HOST=$2
DATABASE=$3
MYSQL_USER=$4
CONCURRENCIES=$5
NUM_TRIALS=$6
IFS="," read -r -a CONCURRENCIES_LIST <<< "$CONCURRENCIES"
NUM_LINES=$(cat $SQL | wc -l)
for CONCURRENCY in "${CONCURRENCIES_LIST[@]}"; do
DIR=$(mktemp -d)
if [ -f init.sql ]; then
# init.sql があれば分割した各ファイルの先頭に挿入する
split -d -l $(($NUM_LINES/$CONCURRENCY+1)) --filter 'sh -c "{ cat init.sql; cat; } > $FILE"' $SQL $DIR/sql
else
split -d -l $(($NUM_LINES/$CONCURRENCY+1)) $SQL $DIR/sql
fi
echo -n "$CONCURRENCY, "
for i in $(seq $NUM_TRIALS); do
TIME_DIR=$DIR/time-$i
mkdir -p "$TIME_DIR"
ls $DIR | grep -v "time-" | xargs -P $CONCURRENCY -I{} bash -c "/usr/bin/time -p -o $TIME_DIR/{}.txt mysql -u${MYSQL_USER} -h $HOST --default-character-set=utf8mb4 $DATABASE < $DIR/{} > /dev/null"
RESULTS=$(cat $TIME_DIR/sql*.txt | grep '^real' | cut -d ' ' -f 2 | sort -n)
MIN=$(echo "$RESULTS" | head -n 1)
MAX=$(echo "$RESULTS" | tail -n 1)
MEDIAN=$(echo "$RESULTS" | tail -n -$(( $CONCURRENCY / 2 + 1 )) | head -n 1) # 厳密じゃない
echo "$MIN, $MEDIAN, $MAX"
if [ "$i" -lt "$NUM_TRIALS" ]; then echo -n ', '; else echo; fi
done
rm -rf $DIR
done
readonly メンテナンス
アップグレードは RDS の blue/green deployment 機能を用いて行いました。 また、サービスを readonly 状態にしてメンテナンスを行いました。
readonly メンテナンスは以下の効果を狙ったものです。
- メンテナンス中でもブログの閲覧が可能になる
- 新バージョンの DB に更新クエリを流す前に read の動作確認と負荷の確認が行える
- 更新クエリが流れる前であれば容易に旧バージョンにロールバックできる
- 新バージョンのDBに更新クエリが流れ始めてからロールバックした場合、新バージョンで更新されたレコードを何らかの方法で旧バージョンの方に書き戻す必要が生じる
- MySQL では新→旧バージョンのレプリケーションはサポートされないので、 binlog を解析して書き戻すか外部ツールで逆方向レプリケーションを組んだりする必要が生じるため大変
メンテナンスの大まかな流れは以下のようになりました。
- サービスの readonly メンテナンスモードを有効にする
- DB を
read_only = 1にする - readonly のままアプリケーションの参照先DBを一時的に green 環境に向けて動作確認
- green 環境 DB を
read_only = 0にして動作確認 - blue 環境に向け直す
- green 環境へのスイッチオーバを行う
- サービスの readonly メンテナンスモードを解除する
1. サービスの readonly メンテナンスモードを有効にする
このために、書き込みを伴う機能や API を事前に洗い出しておき、それらについてメンテ画面を表示する設定をリバースプロキシ (nginx) に実装しました。
アプリケーションで実現する選択肢もありますが、万が一 DB が高負荷に陥っても影響を受けにくい事を期待してこのようにしました。
また、メンテナンスモード中でもスタッフが write を含めた動作確認を行えるよう、特定の Cookie または HTTP ヘッダが付いていればメンテナンス画面を回避できるようにしました。
メンテナンスモードを有効にするかどうか決める変数の設定の例:
http { ... # $readonly_maintenance 変数の値はコンテナに渡す環境変数で指定できる。 # リクエストヘッダ X-Bypass-Maintenance: 1 または Cookie bypass_maintenance=1 # を付けるとメンテナンスモードを回避できる。 map "$readonly_maintenance$http_x_bypass_maintenance$cookie_bypass_maintenance" $should_show_readonly_maintenance_page { default "0"; "1" "1"; "10" "1"; "100" "1"; } ... }
メンテナンス画面表示対象の location で include する設定 (readonly-maintenance.nginx.conf):
if ($should_show_readonly_maintenance_page = "1") { # error_page ディレクティブを1つでも書くと外のコンテキストのものが全部リセットされるので # 全てコピペしつつ 503 だけメンテナンス画面にする error_page 400 /error_page/error_400.html; error_page 413 /error_page/error_413.html; error_page 414 /error_page/error_414.html; error_page 500 /error_page/error_500.html; error_page 501 /error_page/error_501.html; error_page 502 /error_page/error_502.html; #error_page 503 /error_page/error_503.html; error_page 504 /error_page/error_504.html; # メンテナンス画面 # error_maintenance.htmlの内容はメンテナスごとに書き換えてください。 error_page 503 /error_page/error_maintenance.html; return 503; }
メンテ画面表示対象の location で include する:
location / { include /path/to/readonly-maintenance.nginx.conf; ... }
その他、定期実行バッチやジョブワーカも停止しておきます。メンテ中に実行される可能性のあるバッチで冪等でないものは可能であれば時間をずらしておきます。
2. DB を read_only = 1 にする
意図せず更新が走ってしまうのを防ぐため、 MySQL のシステム変数 read_only を有効にします。
RDS ではパラメータグループ経由での変更のため反映されるまでに若干のラグがあります。
3. readonly のままアプリケーションの接続先DBを一時的に green 環境に向けて動作確認
この手順は、 RDS の blue/green deployment にロールバック動作がないために入れています。
green 環境 (新インスタンス) へのスイッチオーバは既存の DB identifier を置き換える事で行われるため、アプリケーション側の接続先 DB ホスト名の設定を変更する必要がないのですが、 blue 環境 (旧インスタンス) の identifier は末尾に -old が付いたものに変わるため、ロールバックする際には結局アプリケーション側の設定変更が必要になってしまいます。
ロールバックの可能性をなるべく減らすためにこのような手順になっています。
4. green 環境 DB を read_only = 0 にして動作確認
green 環境の動作確認のために書き込み可能な設定に変更します。
スイッチオーバ前の green 環境はレプリカ扱いなので、デフォルトの {TrueIfReplica} ではなく 1 にします。
これ以降 green 環境のデータに加えた変更は blue 環境に自動で書き戻されないので、万が一ロールバックすることになった場合は注意が必要です。
その後、事前に用意したQA表を用いて書き込みを含めた動作確認を行います。
一般向けにはメンテナンス画面を表示したままですが、特定の条件を満たすリクエストのみメンテナンス画面を回避できます。
5. blue 環境に向け直す
スイッチオーバの際には blue 環境の DB identifier やホスト名が green 環境にそのまま引き継がれるため、一度 blue 環境に向け直します。
アプリケーション側の接続先 DB ホスト名を変更し、 blue 環境に向け直します。
blue 環境 DB は read_only = 1 のままなので再度書き込みができなくなります。
6. green 環境へのスイッチオーバを行う
スイッチオーバでは blue 環境の DB identifier やホスト名がそのまま green 環境のインスタンスに引き継がれ、 blue 環境インスタンスの DB identifier の末尾には -old が付き、ホスト名も変更されます。
今回の手順では 4. で明示的に readonly=0 としているので関係ありませんが、 green 環境のパラメータグループで read_only=1 になっていても、スイッチオーバの際に MySQL のランタイム変数が自動で read_only=0 に書き換わり、強制的に書き込み可能になるようです (2023/05時点)。
readonly のままスイッチオーバを行おうとしている場合には注意が必要です。
7. サービスの readonly メンテナンスモードを解除する
1 と逆の手順でサービスの readonly メンテナンスモードを解除します。
アップグレード後に出た不具合
mysql_native_password の Deprecation warning がセッション毎に出る
以下のメッセージがセッション毎にエラーログに出力されます。
[Warning] [MY-013360] [Server] Plugin mysql_native_password reported: ''mysql_native_password' is deprecated and will be removed in a future release. Please use caching_sha2_password instead'
MySQL 8.0.34 以降で mysql_native_password 認証プラグインが Deprecated になったためにこのメッセージが出るようになったようです。今回は認証プラグインの変更を見送ったので出ないようにしたいのですが、ピンポイントで止める方法は無さそうなのでひとまず我慢しています。
極端な日時または invalid な日時を含むクエリがエラーになる
日時関連でエラーになる箇所はアップグレード前にも修正していましたが、一部で漏れがあり、 0000-00-00 00:00:00 や 10000年の日時を含むクエリがエラーになる部分がありました。
また、かなりのエッジケースではありますが、0000年2月のサイトマップを生成する処理がエラーになっていました。原因は閏年の判定が Perl と MySQL で異なることによるものでした。 Perl の DateTime モジュールでは0000年が閏年と判定されたため0000年2月29日までの範囲でクエリが発行されましたが、 MySQL では閏年ではないと判定され、不正な日時としてバリデーションエラーになっていました。
ふりかえり、感想
事前のアプリケーション側の修正を入念に行っていただけたこと、 staging 環境でリハーサルした上で詳細な手順を作って挑んだこともあって、一部不具合は出たものの特に大きなトラブルもなく完了しました。
メンテナンスの所要時間について、告知エントリにもある通り今回は 13:00〜14:45の1時間45分で、そのほとんどの時間 readonly 状態になっていました。
blue/green deployment にはロールバック機能が無いため、スイッチオーバ後の手動ロールバック (-old の付いた DB インスタンスへの向け直し) の可能性をできる限り減らすためにスイッチオーバ前に一度 green 環境に向け変えて動作確認する手順を行ったこともあり、手順が多く所要時間が長めになっています。新バージョンの環境 (green 環境) の構築が楽になる以外に blue/green deployment の利点を活かせていない気がするので、レプリカを作って昇格させるなどの切り替え方法でも良かったかも知れません。
blue/green deployment に、 readonly を維持したままスイッチオーバする機能やロールバック機能 (readonly を解除する前であれば安全にロールバックできる。 green 環境への書き込みが開始された後はスプリットブレインを承知の上で行う) が実装されればもっと便利になりそうだなと思いました。
たとえブログが閲覧可能であっても平日の日中にブログの投稿や管理画面等の機能が長時間停止してしまうのは特にサポートや法人向けの業務に大きな影響が出てしまうので、現状の所要時間だと日中に行うのはなかなか厳しそうです。次回以降の同様のメンテナンスは業務時間内を避けて夜間か早朝に行う事を検討しています。