こんにちは、マンガメディア第1チームでGigaViewerのSREを担当しているの ![]() id:s-shiro です。
id:s-shiro です。
この記事は、はてなのSREが毎月交代で書いているSRE連載の9月号です。8月の記事は ![]() id:walnuts1018 さんの OpenCostを使ってEKSクラスタのコストを可視化しました でした。
id:walnuts1018 さんの OpenCostを使ってEKSクラスタのコストを可視化しました でした。
CDN移行祭り開催!!!
7月、8月とはてな社内では他社CDNからCloudFrontへ切り替える移行祭りが開催されていました。
CloudFrontのアクセスログの出力方法にはレガシー(その名の通り古くからある)とv2(レガシーに変わるとされる新しいログ)の2つがあるのですが、CDN契約の関係上、移行の期日が決まっていたこともあり、移行時点ではひとまず設定が簡単で利用実績のあるレガシーを使っていました。
移行がひと段落して、ログもv2にしようとなったとき「loggingの設定ひとつで切り替わってくれるんでしょ?」と思っていたのですが、調べてみるとv2ログはCloudWatch Logsの仕組みを使っているらしく、一筋縄ではいかないことが分かりました。
- CloudWatch Logsの仕組みを使っており、Terraform管理しようとするとログを出力するだけでも3種類のリソースを作成する必要がある(Webコンソールからなら簡単なんですけどね......)
- 料金体系もCloudWatch Logsのものが適用され、レガシーログよりもシビアなコストコントロールが必要
「ログはS3に出力すればコスト回避できるんでしょ?」と思いきや、その場合にもCloudWatch Vended Logsなるものの料金を支払う必要があるという建て付け。レガシーログではS3に産地直送できたのに......。
一方v2ログでは、これまでレガシーログではできなかったS3バケットへ出力する際のパスを変更するということができるようになりました。これによりパーティション射影を柔軟に設定でき、ログの分析基盤を作りやすくなったと言えるでしょう。
レガシーログではパーティショニングのために、一度CloudFrontが出力したログをLambda関数を使って別のパスに移動する方法が紹介されていましたが、v2ログではそういった手間がなくなりました。
CloudFront v2ログをパーティション射影してAthenaからクエリできるようにする方法は各所で紹介されているのでそちらに解説を譲るとして、ここではAWSから提供されているドキュメント以上の 便利に使えるちょっとした工夫 を紹介しようと思います
- CDN移行祭り開催!!!
- Terraformで管理するv2ログの3つのリソース
- timestampはデフォルトではログに出力されない
- 任意の値をパーティショニングに使う
- 複数バケットをひとつのテーブルにまとめる
- テーブル定義をTerraform化する
- 感想
Terraformで管理するv2ログの3つのリソース
CloudFront v2ログを出力するためには、前述したCloudWatch Vended Logsという仕組みを使う必要があります。
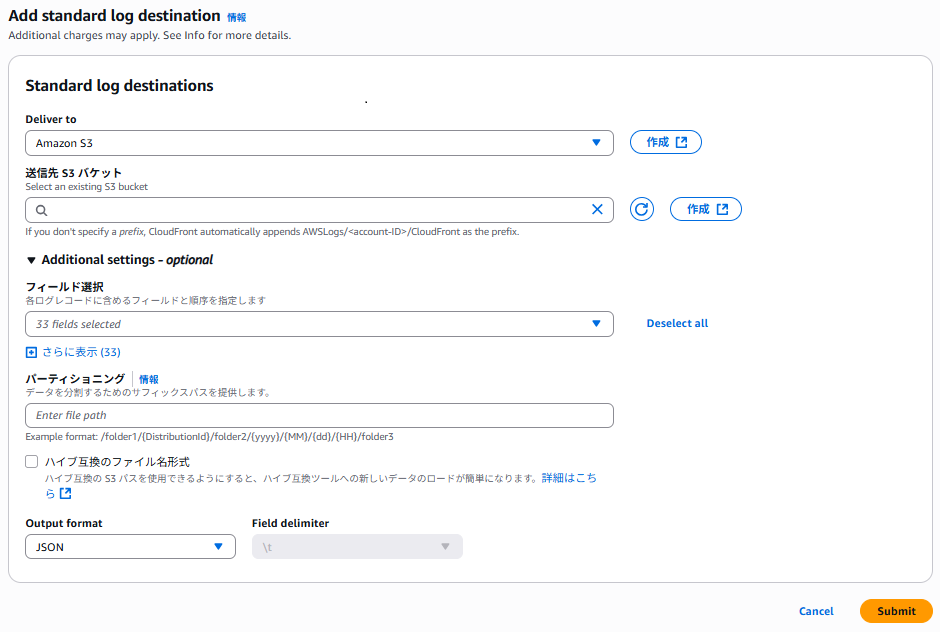
Webコンソールからの設定項目はそれほど多くないように見えるのですが、実は裏側ではCloudWatch Logsに関連する3つのリソースが作成されています。
Terraformのドキュメントにサンプルコードがあり、そのことが確認できます。
- aws_cloudwatch_log_delivery_source
- ログの送信元、ここではCloudFrontディストリビューション
- aws_cloudwatch_log_delivery_destination
- ログの送信先、S3バケットやFirehoseが選べる。ここではS3
- aws_cloudwatch_log_delivery
- 上記2つのリソースをたばねて、配送元と配送先を接続するもの
それと注意点として、CloudFrontディストリビューションやS3バケットのリージョンに関係なく aws_cloudwatch_log_delivery のリージョンは us-east-1 を指定する必要があります。
timestampはデフォルトではログに出力されない
ログに出力できる項目をカスタマイズできるのですが、デフォルトの設定そのままだと timestamp が出力されません。
Terraformのコード上では、ログに出したい全てのフィールドを明示的に記述する必要があります。
locals {
# サポートされているフィールド
# https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/standard-logging.html#standard-logging-real-time-log-selection
# デフォルトのフィールドとリアルタイムログフィールドで指定可能なもの
cloudfront_log_fields = [
{ name = "timestamp(ms)", type = "string" },
{ name = "date", type = "string" },
{ name = "time", type = "string" },
{ name = "time-taken", type = "string" },
{ name = "time-to-first-byte", type = "string" },
{ name = "asn", type = "string" },
{ name = "c-ip", type = "string" },
{ name = "c-port", type = "string" },
{ name = "c-country", type = "string" },
{ name = "cs-protocol", type = "string" },
{ name = "cs-protocol-version", type = "string" },
{ name = "cs-bytes", type = "string" },
{ name = "cs-method", type = "string" },
{ name = "cs(Host)", type = "string" },
{ name = "cs-uri-stem", type = "string" },
{ name = "sc-status", type = "string" },
{ name = "cs(Referer)", type = "string" },
{ name = "cs(User-Agent)", type = "string" },
{ name = "cs-uri-query", type = "string" },
{ name = "cs(Cookie)", type = "string" },
{ name = "sc-bytes", type = "string" },
{ name = "sc-content-type", type = "string" },
{ name = "sc-content-len", type = "string" },
{ name = "sc-range-start", type = "string" },
{ name = "sc-range-end", type = "string" },
{ name = "x-edge-location", type = "string" },
{ name = "x-edge-result-type", type = "string" },
{ name = "x-edge-request-id", type = "string" },
{ name = "x-edge-response-result-type", type = "string" },
{ name = "x-edge-detailed-result-type", type = "string" },
{ name = "x-host-header", type = "string" },
{ name = "x-forwarded-for", type = "string" },
{ name = "ssl-protocol", type = "string" },
{ name = "ssl-cipher", type = "string" },
{ name = "fle-status", type = "string" },
{ name = "fle-encrypted-fields", type = "string" },
{ name = "cache-behavior-path-pattern", type = "string" },
{ name = "origin-fbl", type = "string" },
{ name = "origin-lbl", type = "string" },
]
}
~ 中略 ~
resource "aws_cloudwatch_log_delivery" "this" {
delivery_source_name = <aws_cloudwatch_log_delivery_sourceのname>
delivery_destination_arn = <aws_cloudwatch_log_delivery_sourceのARN>
record_fields = [for field in local.cloudfront_log_fields : field.name]
s3_delivery_configuration {
enable_hive_compatible_path = false
suffix_path = "/${パーティショニングに使う値}/{yyyy}/{MM}/{dd}/{HH}"
}
}
timestampには timestamp と timestamp(ms) があります。ここでは後者を出力する設定にしています。
ちなみにこのフィールドのリストは、Athenaでクエリする対象のGlueテーブルの定義にも使うので、local変数にするなり、モジュール化するなりして 再利用性を持たせておくのがおすすめです。
任意の値をパーティショニングに使う
AWSドキュメントには、ログ出力先のパス指定で利用できるいくつかのプレースホルダーが紹介されています。
- {DistributionId}、または {distributionid}
- {yyyy}
- {MM}
- {dd}
- {HH}
- {accountid}
CloudFrontはCDNという仕組み上、ユーザーからのリクエストを最初に受ける口として利用されることが多く、オリジンサーバーと比べて膨大な量のログが出力される可能性が高いです。そのため、パーディションはできるだけ細かく区切っておいた方がよいでしょう。
きっちり {HH} まで使って1時間単位でパーティショニングしておくのが無難です。
プレースホルダーとして DistributionId が提供されているので各所のブログなどでも、この値をパーディションに設定している例が多いのですが、クエリする側のことを考えると SQLを書くたびにこの謎の文字列をクエリに埋め込む必要がある というのは使い勝手がよくありません。
パーティションには、実際のユースケースでどんなSQLを書くことが多いのかを想定して、人間にとって分かりやすく、かつスキャン量を最適化できるような値を設定すべきです。
GigaViewerはマルチテナントサービスなので、テナントが1つ追加されるたびにCloudFrontのディストリビューションで配信するドメインが複数個増えるという性質があります。新規テナントのサービスローンチ直後などには、特定のテナントやドメイン名に絞ってログを確認したい場合が多くあります。一方、Error Rateなどシステム全体の指標を計測したい場合には、全テナントのログをまとめて集計することもあります。
そういったユースケースに対応するかたちで、全テナントのログを一つのテーブルにまとめつつ ドメイン名でフィルターした際にはパーティションが利用される という構成をとることにしました。
"/${ドメイン名}/{yyyy}/{MM}/{dd}/{HH}"
ちなみに私はまだ利用したことがないのですが、最近CloudFront SaaS Managerというサービスが出たらしく、これを使うとマルチテナント環境でディストリビューションの管理が簡単になるようです。とはいえテナントごとにドメインが増えること自体は変わらずですね。
複数バケットをひとつのテーブルにまとめる
CloudFrontディストリビューションと、そのログのライフサイクルは同じなので、ログの出力設定(aws_cloudfront_log_delivery)や出力先のS3バケットは、Terraform上は同じWorkspaceに置くのがコード管理しやすいでしょう。
前述したとおりGigaViewerでは、複数のテナントのアクセスログを一つのテーブルで管理したいのですが、テーブルに対応するログの出力先であるS3バケットは1つになるとは限らないので、テーブル定義をマルチバケットに対応させる必要があります。
CREATE EXTERNAL TABLE cloudfront_logs.cloudfront_logs (
`timestamp(ms) STRING`,
`time-taken STRING`,
`time-to-first-byte STRING`,
`asn STRING`,
`c-ip STRING`,
`c-port STRING`,
`c-country STRING`,
`cs-protocol STRING`,
`cs-protocol-version STRING`,
`cs-bytes STRING`,
`cs-method STRING`,
`cs(Host) STRING`,
`cs-uri-stem STRING`,
`sc-status STRING`,
`cs(Referer) STRING`,
`cs(User-Agent) STRING`,
`cs-uri-query STRING`,
`cs(Cookie) STRING`,
`sc-bytes STRING`,
`sc-content-type STRING`,
`sc-content-len STRING`,
`sc-range-start STRING`,
`sc-range-end STRING`,
`x-edge-location STRING`,
`x-edge-result-type STRING`,
`x-edge-request-id STRING`,
`x-edge-response-result-type STRING`,
`x-edge-detailed-result-type STRING`,
`x-host-header STRING`,
`x-forwarded-for STRING`,
`ssl-protocol STRING`,
`ssl-cipher STRING`,
`fle-status STRING`,
`fle-encrypted-fields STRING`,
`cache-behavior-path-pattern STRING`,
`origin-fbl STRING`,
`origin-lbl STRING`
)
PARTITIONED BY (
`partition_name` STRING,
`partition_datehour` STRING
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'paths'='timestamp(ms),date,time,time-taken,time-to-first-byte,asn,c-ip,c-port,c-country,cs-protocol,cs-protocol-version,cs-bytes,cs-method,cs(Host),cs-uri-stem,sc-status,cs(Referer),cs(User-Agent),cs-uri-query,cs(Cookie),sc-bytes,sc-content-type,sc-content-len,sc-range-start,sc-range-end,x-edge-location,x-edge-result-type,x-edge-request-id,x-edge-response-result-type,x-edge-detailed-result-type,x-host-header,x-forwarded-for,ssl-protocol,ssl-cipher,fle-status,fle-encrypted-fields,cache-behavior-path-pattern,origin-fbl,origin-lbl'
)
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<ダミーの適当なバケット名>/v2/'
TBLPROPERTIES (
'projection.enabled'='true',
'projection.partition_domain.type'='injected',
'projection.partition_bucket.type'='injected',
'projection.partition_datehour.type'='date',
'projection.partition_datehour.format'='yyyy/MM/dd/HH',
'projection.partition_datehour.interval'='1',
'projection.partition_datehour.interval.unit'='HOURS',
'projection.partition_datehour.range'='2025/07/01/00,NOW',
'storage.location.template'='s3://${partition_bucket}/${partition_domian}/${partition_datehour}/'
)
CREATE TABLE文はこんな感じになります。ポイントは LOCATION = <ダミーの適当なバケット名> を指定しておいて、パーティション射影の設定( TBLPROPERTIES )では 'storage.location.template'=s3://${partition_bucket}/...... とLOCATIONに指定した値とは関係なく異なるバケットを指定できるようにすることです。
またパーティション射影に使える型はenum, integer, date, injectedの4つがあり、一見するとenum型を使えばよいかと思うのですが、将来的にパーディションに使うドメイン名やバケット名は増えていくのでenum型で固定長のリストを指定してしまうと、テナントが増えるたびにALTER TABLEでenumのリストを更新していく手間がかかってしまいます。
そのため partition_domain や partition_bucket などの値は、クエリする側が値を指定できるように injected 型を指定しています。
SELECT
*
FROM
cloudfront_logs.cloudfront_logs
WHERE
partition_bucket = 'production-cloudfront-logs'
AND
partition_domain in ("a.example.com", "b.example.com)"
これでクエリ実行時にWHERE句の中に書かれた値がパーティションとして使われるようになります。
テーブル定義をTerraform化する
テーブルのスキーマも、できればTerraformで管理したいものです。Terraformでテーブルを作成する際にはGlue Tableのリソースを使います。
resource "aws_glue_catalog_database" "cloudfront_logs" {
catalog_id = local.account_id
name = local.cloudfront_log_database_name
}
resource "aws_glue_catalog_table" "cloudfront_logs" {
catalog_id = local.account_id
name = local.cloudfront_log_table_name
database_name = local.cloudfront_log_database_name
table_type = "EXTERNAL_TABLE"
parameters = {
"projection.enabled" = "true",
"projection.partition_domain.type" = "injected",
"projection.partition_environment.type" = "injected",
"projection.partition_datehour.type" = "date",
"projection.partition_datehour.format" = "yyyy/MM/dd/HH",
"projection.partition_datehour.interval" = "1",
"projection.partition_datehour.interval.unit" = "HOURS",
"projection.partition_datehour.range" = "2025/07/01/00,NOW",
"storage.location.template" = "s3://$${partition_bucket}/$${partition_domain}/$${partition_datehour}/"
}
partition_keys {
name = "partition_bucket"
type = "string"
}
partition_keys {
name = "partition_domain"
type = "string"
}
partition_keys {
name = "partition_datehour"
type = "string"
}
storage_descriptor {
# バケット名はクエリ時にpartition_environmentを指定することで変更できるようにするため、ここではダミーの値を入れておく
location = "s3://<ダミーの適当なバケット名>/v2"
input_format = "org.apache.hadoop.mapred.TextInputFormat"
output_format = "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"
compressed = true
ser_de_info {
serialization_library = "org.openx.data.jsonserde.JsonSerDe"
parameters = {
"paths" = join(",", [for field in local.cloudfront_log_fields : field.name])
}
}
dynamic "columns" {
for_each = local.cloudfront_log_fields
content {
# terraform apply後にGlueの側で小文字にされるが、terraformとしては大文字で作成しようとするので毎回plan差分が出る
# terraform側でlowerしてあげることで差分が解消される
name = lower(columns.value.name)
type = columns.value.type
}
}
}
lifecycle {
create_before_destroy = true
}
}
こんな感じ。ここで先ほど定義したCloudFrontログの出力フィールドの一覧 local.cloudfront_log_fields が再利用できます。
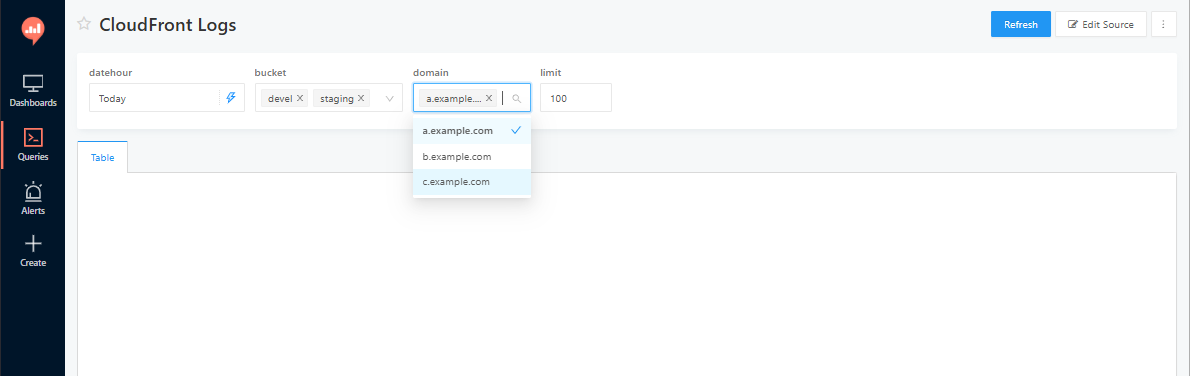
マンガメディアチームではRedashを使って、バケット名やドメイン名をドロップダウンで選択できるようにしています
感想
CloudWatch Logsがクラウド破産防止のポイントとして紹介された資料があったり、実際に弊社でも負荷試験のエラーログを意図せずCloudWatch Logsに大量放出して料金が跳ね上がってしまった経験があり、v2ログに移行するにあたっては「Cloud Watch Logsのコストが暴発するのではないか?」と不安になりながら、毎日コストを確認しつつ少しずつ移行したので、なんだかんだで移行に1か月くらいかかってしまいました。
CloudWatch Logsのログ取り込み量削減はクラウド破産防止の重要ポイント
今年(2025年)のAWS SummitのSynspectiveさんの発表資料より
実際コストは若干増えた程度 だったので、しっかり準備して利用すればCloudWatch Logsは、とても便利なサービスだと思いますよ。
また、移行にあたって細やかなカスタマイズを通して、使いやすいログ基盤の構築ができたのではないかと思っています。