こんにちは、サービスプラットフォームチーム アルバイトの ![]() id:walnuts1018 です。
この記事は、はてなの SRE が毎月交代で書いている SRE 連載の 8 月号です。7 月の記事は
id:walnuts1018 です。
この記事は、はてなの SRE が毎月交代で書いている SRE 連載の 8 月号です。7 月の記事は ![]() id:masayoshi さんの はてなで最近実施している SRE 研修の紹介 でした。
id:masayoshi さんの はてなで最近実施している SRE 研修の紹介 でした。
今回は、社内共用の画像変換プロキシである、「Scissors」というサービスを EC2 から EKS に移行したお話をしたいと思います。
- 画像変換プロキシについて
- 課題点
- サービスプラットフォームチームにおける EKS
- やりたいこと
- 移行に関する懸念点
- Scissors 専用の Node を用意する
- Pod / Node のオートスケール
- オートスケールの検証
- リリース
- まとめ/ふりかえり
画像変換プロキシについて
はてなでは「Scissors」という内製の画像変換プロキシがあり、はてなブログや GigaViewer のサムネイルなど、様々な場所で利用されています。
クエリパラメータで width / height を指定することにより、画像をリサイズ/トリミングしたり、quality を指定して jpg のデータ容量を削減したりすることができます。
課題点
Scissors は EC2 上で動いており、以下のような課題がありました。
- EC2 のスケールアップ/インが手動で行われているため、リクエストの増減に迅速に対応できない
- スポットインスタンスなどを活用したコスト最適化ができない
そこで今回これらの課題を解決するために、Scissors を EKS に移行することにしました。
サービスプラットフォームチームにおける EKS
サービスプラットフォームチームでは 4 年ほど前から EKS クラスタを運用しており、ラボサービスを含めた複数のアプリケーションが同一クラスタ上で稼働しています。 今回はこの既存の EKS クラスタに Scissors を同居させる形で運用を行うことにしました。
やりたいこと
EKS に移行することで達成したい内容は以下の通りです。
- Pod / Node のオートスケールにより、リクエストの増減に対応する
- スポットインスタンスを利用し、コスト削減を行う
- 既存の CI/CD フローを活用し、より効率的な管理を行う
移行に関する懸念点
EKS 上で Scissors を動かすにあたって、以下のような懸念点がありました。
- CPU、メモリを比較的多く消費するため、他 Pod のスケジューリングや動作に影響が出るのではないか
- Pod / Node のオートスケールが間に合わないのではないか
これらの懸念点を解消するために行った対策や検証をご紹介していきます。
Scissors 専用の Node を用意する
他サービスの Pod に影響を与えないよう、NodeSelector、Taint 、Toleration を利用して Scissors の Pod のみが動作する Node を用意しました。
NodeSelectorは、その Pod が どの Node にスケジューリングされなければならないかを指定します。Node についたラベルを用いて指定することができます。1

Taintは、その Node が、Pod にスケジューリングされないようにするためのものです。Taintがついた Node には、基本的に Pod がスケジューリングされません。
Tolerationは、Taint がついた Node に Pod をスケジューリングするためのものです。
Taintがついている Node には、一致するToleration が設定されている Pod のみスケジューリングされます。ただし、スケジューリングが許可されるというだけで、必ずしもその Node にスケジューリングされるわけではありません。2
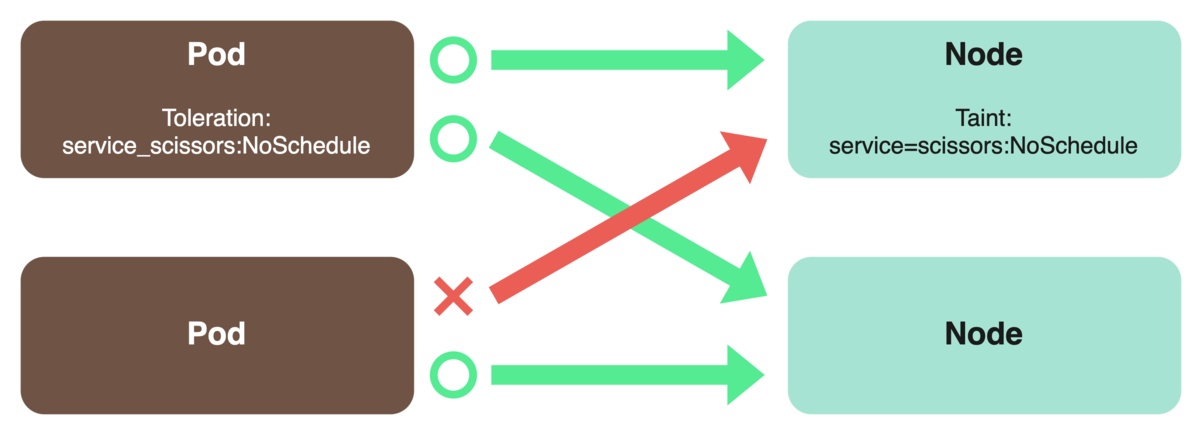
これらの機能を併用することで、Scissors 専用の Node を用意することができます。
ただし、fluentbit など、すべての Node で動作するべき Pod もあるため、そのような Pod にもTolerationを設定し、例外的に 専用 Node にスケジューリングされるようにしました。
特に、以下のような Toleration を設定しておくと、すべての Taint を許容することができるので便利です。3
tolerations: - operator: "Exists"
Pod / Node のオートスケール
今回、Pod のオートスケールにはHorizontalPodAutoscaler、Node のオートスケールには Spot の Ocean という機能を利用しました。
HorizontalPodAutoscaler は、CPU 使用率やメモリ使用率などのメトリクスに基づいて Pod のレプリカ数を自動的に調整する機能です。当然、Node のリソース空きがないと Pod のスケールアップができませんが、 Spot Ocean の Headroom という機能により常に余剰リソースを確保しておくことで、Node のスケールを待たずともスパイクに対応できるようにしました。
Spot Ocean については、「はてラボ」のサービスも利用している EKS クラスタの構成と運用について でも紹介されています。ぜひご覧ください。
オートスケールの検証
オートスケールを設定する際には、
- Pod のリソース要求をどれくらいにするのか
- HorizontalPodAutoscaler の閾値をどれくらいに設定するのか
- Pod 数の最小値/最大値をどれくらいに設定するのか
- Headroom をどれくらいに設定するのか
などを考える必要があります。
今回これらの設定を検証するために、k6を用いた負荷テストを行いました。
k6 は、Grafana Labsが開発した負荷テストツールで、JavaScript を使って簡単にテストを記述することができます。
今回は、本番環境のメトリクスの最大値などを参考にrps(request per second)の値を設定し、負荷試験を実施しました。
また、一台のクライアントで大規模テストを行うため、公式ドキュメントを元に以下のような設定を行いました。
sysctl -w net.ipv4.ip_local_port_range="1024 65535": 使用できるポートの範囲を増やします。デフォルトでは 32768〜60999 になっています。sysctl -w net.ipv4.tcp_timestamps=1&sysctl -w net.ipv4.tcp_tw_reuse=1: TCP のTIME-WAIT状態(通信が終わってから、コネクション切断まで一定時間待っている状態)の時、そのソケットを一秒後に再利用できるようにします。デフォルトでは、CLOSEDにならないと使えません。ulimit -n 250000: 開くことができるファイル数の上限を増やします。
これらの設定を行うことで、一台のクライアントで 高いrpsを出すことができました。
負荷試験 1 回目
一度目の負荷試験では、以下のような結果が得られました。
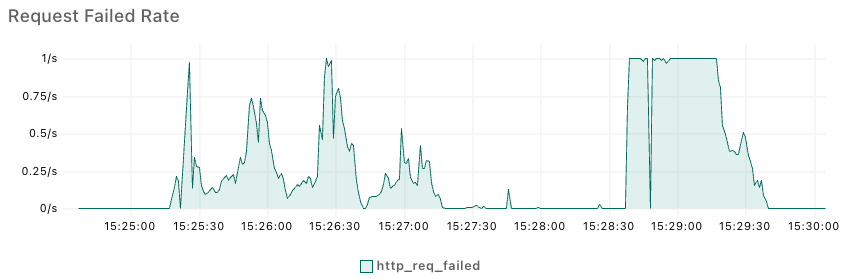
Failed Rateこのグラフはリクエストが失敗した割合を示しています。Failed Rateが 1/s の時、全てのリクエストが失敗していることになります。
この結果を見ると、後半のFailed Rateが 100%に張り付いていることがわかります。この時、Pod は十分な数までスケールアップできていましたが、リクエストは全て失敗していました。
この現象の原因は、Readiness Probeでした。
Readiness Probeは Pod の起動直後、まだ初期化処理が完了していない時にリクエストを振り分けないようにするための機能です。例えば以下のようにすると、GET /server/availが 200 を返すまで起動が完了していないとみなし、Service からのリクエストが振り分けられません。
readinessProbe: httpGet: port: 80 path: /server/avail initialDelaySeconds: 5 timeoutSeconds: 5
今回はこのReadiness Probeがサイドカーにのみ設定されており、Scissors 本体のコンテナに設定するのを忘れていました。
負荷試験 2 回目
Readiness Probe を設定し直した後、再度負荷試験を行いました。その他の条件は全く同じです。
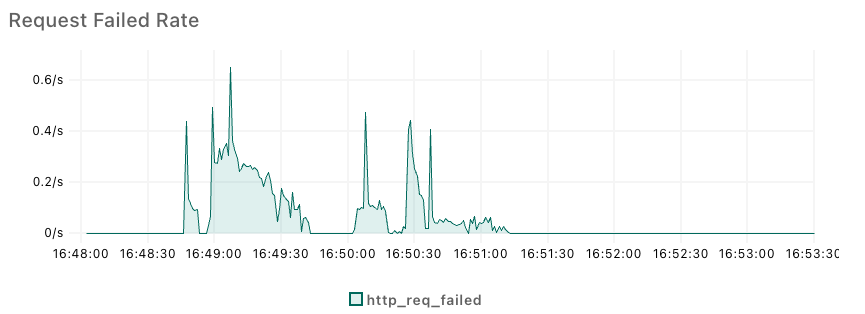
Failed Rate後半を中心にFailed Rateが大きく改善されていることがわかります。これで、Pod のスケールアップが正常に機能することが確認できました。
その後も、Headroomの設定や、HorizontalPodAutoscalerの閾値を調整することで Failed Rate の改善を行い、無事本番に出せる性能を獲得することができました。
リリース
EKS 環境 への移行は、Route53 の荷重ルーティングを用いて、新旧 ALB の Weight を少しずつ変更していくことで行いました。 まずは比較的影響の少ないドメインを切り替え、問題がないことを確認した後、他のドメインも順次切り替えていきました。
切り替え完了後、旧環境へのリクエストがないことを確認した後、旧環境を停止し、移行作業を完了しました。
まとめ/ふりかえり
EKS への移行により、リクエストの増減に迅速に対応できるようになった上、約 $800 / month のコスト削減を行うことができました。 また、事前に本番のメトリクスから目標 rps を設定し、負荷試験を行うことで、安心して本番環境にリリースすることができました。
デプロイにあたっては ![]() id:masayosu さんに多くの作業を手伝っていただきました。ありがとうございました。
id:masayosu さんに多くの作業を手伝っていただきました。ありがとうございました。
今後も Scissors の改善に取り組んでいきたいと思います。